At this year’s re:Invent, AWS introduced a new service (currently in preview) call Lambda. Mitch Garnaat already introduced the service to the advent audience in the first post of the month .
Take a minute to read Mitch’s post if you haven’t already. He provides a great overview of the service, it’s goals, and he’s created a handy tool, Kappa , that simplifies using the new service.
Going Deeper
Of course Mitch’s tool is only useful if you already understand what Lambda does and where best to use it. The goal of this post is to provide that understanding.
I think Mitch is understating things when he says that “there are some rough edges”. Like any AWS service, Lambda is starting out small. Thankfully–like other services–the documentation for Lambda is solid.
There is little point in creating another walk through setting up a Lambda function. This tutorial from AWS does a great job of the step-by-step.
What we’re going to cover today are the current challenges, constraints, and where Lambda might be headed in the future.
Challenges
1. Invocation vs Execution
During a Lambda workflow 2 IAM roles are used. This is the #1 area where people get caught up.
A role is an identity used in the permissions framework of AWS. Roles typically have policies attached that dictate what the role can do within AWS.
Roles are a great way to provide (and limit) access within passed access and secret keys around.
Lambda uses 2 IAM roles during it’s workflow, an invocation role and an execution role. While the terminology is consistent within computer science it’s needlessly confusing for some people.
Here’s the layman’s version:
- Invocation role => the trigger
- Execution role => the one that does stuff
This is an important difference because while the execution role is consistent in the permissions it needs, the invocation role (the trigger) will need different permissions depending on where you’re using you Lambda function.
If you’re hooking your Lambda function to an S3 bucket, the invocation role will need the appropriate permissions to have S3 call your Lambda function. This typically includes the lambda:InvokeAsync permission and a trust policy that allows the bucket to assume the invocation role.
If you’re hooking your function into a Kinesis event stream, the same logic applies but in this case you’re going to have to allow the invocation role access to your Kinesis stream since it’s a pull model instead of the S3 push model.
The AWS docs sum this up with the following semi-helpful diagrams:
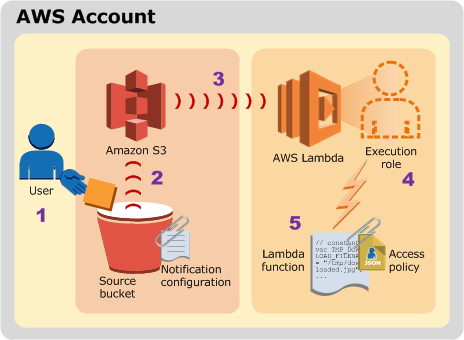
S3 push model for Lambda permissions
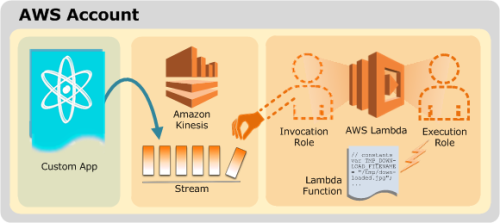
Kinesis pull model for Lambda permissions
Remember that your invocation role always needs to be able to assume a role (sts:AssumeRole) and access the event source (Kinesis stream, S3 bucket, etc.)
2. Deployment of libraries
TL:DR Thank Mitch for starting Kappa .
The longer explanation is that packaging up the dependencies of your code can be a bit of the pain. That’s because we have little to no visibility into what’s happening.
Until the service and associated tooling matures a bit, we’re back to world of printf or at least
console.log(“Did execution get this far?”);For Lambda a deployment package is your javascript code and any supporting libraries. These need to be bundled into a .zip file. If you’re just deploying a simple .js file, .zip it and you’re good to go.
If you have addition libraries that you’re providing, buckle up. This ride is about to get real bumpy.
The closest things we have to a step-by-step on providing additional libraries is this step from one of the AWS tutorials.
The instructions here are to install a separate copy of node.js , create a subfolder, and then install the required modules via npm.
Now you’re going to .zip your code file and the modules from the subfolder but not the folder itself. From all appearances the .zip needs to be a flat file.
I’m hopeful there will be more robust documentation on this soon but in the meantime please share your experiences in the AWS forums or on Twitter.
Constraints
As Lambda is in preview there are additional constraints beyond what you can expect when it is launched into production.
- Functions must executed in <= 1GB of memory
- Functions must complete execution in <= 60 seconds
- Functions must be written in Javascript (run on node.js )
- Functions can only access 512 MB of temp disk space
- Functions can only open 1024 file descriptors
- Functions can only use 1024 threads+processes
These constraints also leads to some AWS recommendations that are worth reading and taking to heart however one stands out above all the others.
“Write your Lambda function code in a stateless style”, AWS Lambda docs.
This is by far the best piece of advice that one can offer when it comes to Lambda design patterns. Do not try to bolt state on using another service or data store. Treat Lambda as an opportunity to manipulate data mid-stream. Lambda functions execute concurrently.
Thinking of it in functional terms will save you a lot of headaches down the road.
The Future?
One of the most common reactions I’ve heard about AWS Lambda is, “So what?”. That’s understandable but if you look at AWS’ track record, they ship very simple but useful services and iterate very quickly on them.
While Lambda may feel limited today, expect things to change quickly. Kinesis, DynamoDB, and S3 are just the beginning. The “custom” route today provides a quick and easy way to offload some data processing to Lambda but that will become exponentially more useful as “events” start popping up in other AWS services.
Imagine trigger Lambda functions based on SNS messages, CloudWatch Log events, Directory Service events, and so forth.
Look to tagging in AWS as an example. It started very simple in EC2 and over the past 24 months has expanded to almost every service and resource in the environment. Event’s will most likely follow the same trajectory and with every new event Lambda gets even more powerful.
Additional Reading
Getting in on the ground floor of Lambda will allow you to shed more and more of your lower level infrastructure as more events are rolled out to production.
Here’s some holiday reading to ensure you’re up to speed:
- Watch “Getting Started with AWS Lambda”, MBL202 from this year’s re:Invent
- Read Jeff Barr’s post introducing Lambda, “AWS Lambda - Run Code in the Cloud”"
- Read through the Lambda developer guide
- Re-read Mitch’s post from earlier this month