Originally presented at the AWS Summits in Santa Clara, NYC, Washington D.C., and Toronto in 2019. This was also presented at the inaugural AWS re:Inforce in Boston.
Security is often misunderstood and addressed in the last stages of a build. Operationally, it’s ignored until there is an emergency. In this talk, we review several advanced security processes and discuss how too easily automate them using common tools in the AWS Cloud.
This approach helps you and your team increase the security of your build while reducing the overall operational requirement of security in your stack. Leave this dev chat with everything you need to get started with automating security.
Slides

The goal of cybersecurity is often stated in technical terms. I think there's a much simpler way to look at it. The goal of any and all cybersecurity activities is, "To make sure that systems work as intended...and only as intended".
Security is fundamentally a software/hardware quality issue. No one wakes up thinking they want to write 💩 code today. This goal is far more conducive to solving the problem vs. blaming or focusing on cybercriminals and hackers.
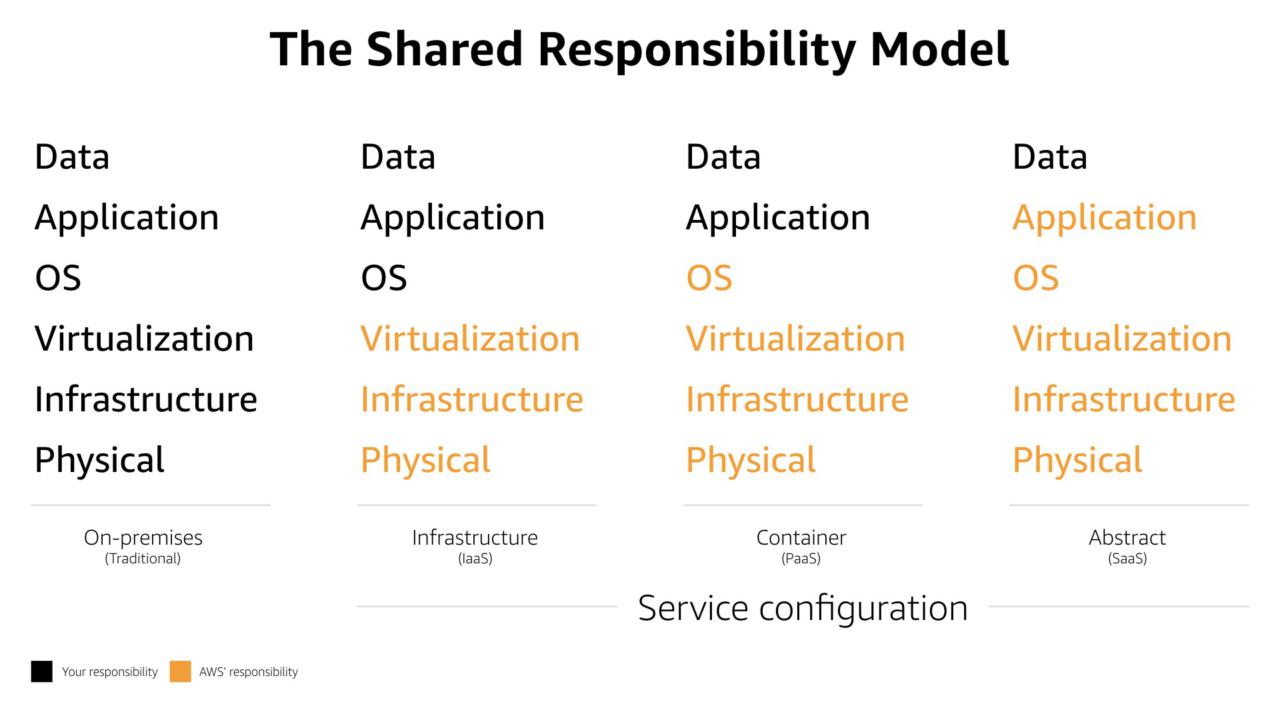
The Shared Responsibility Model is often positioned as a security model. In actuality is governs how everything is done in the AWS Cloud.
There are business and security wins as you move more and more of your build to the right side of the model towards "abstract" type services.
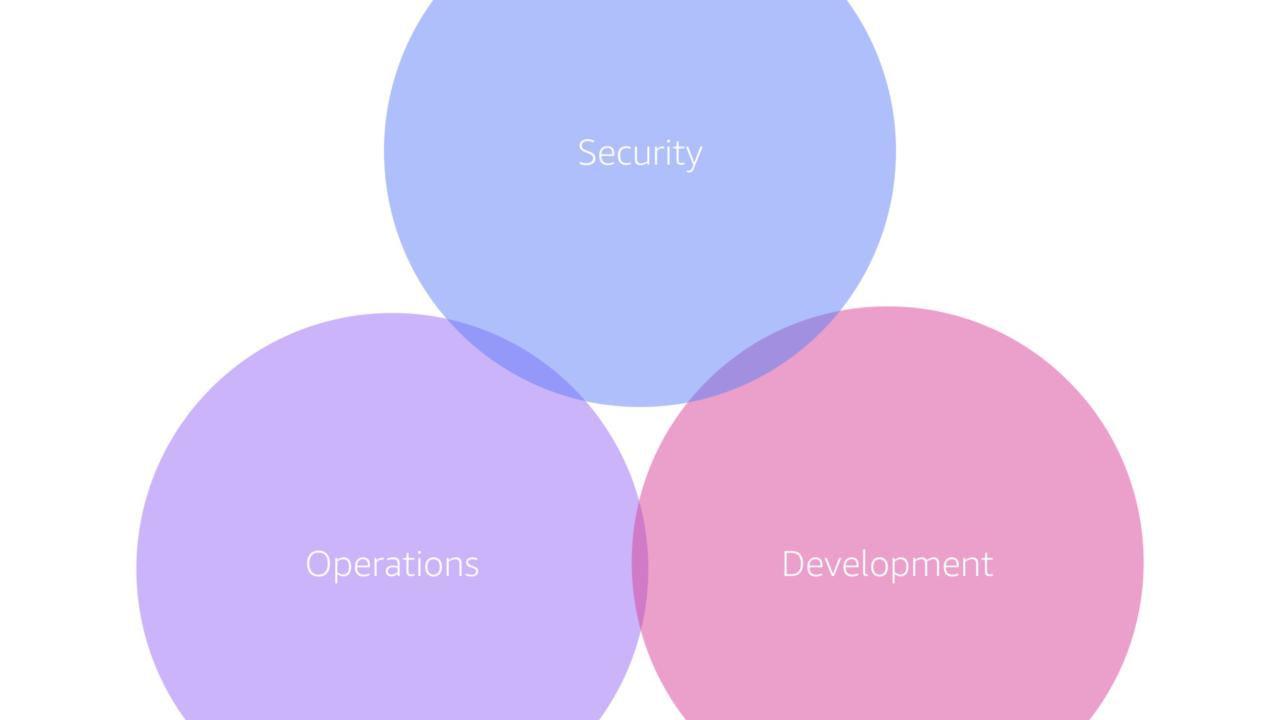
Within most organizations, security, operations, and development are completely different teams with different reporting structures. That's crazy given that they have a shared goal.
Development and operations have been (slowly) starting to come together but security is still on the outside...despite the marketing push around the term 🥶 DevSecOps 🥶 which still isn't a thing.

Really these teams should start coming together. Whether that means a two pizza team approach (a la AWS) or another governance model, the important thing is that they work together to solve problems for the customer.

One tool that really makes this clear is the AWS Well-Architected Framework.
The framework helps you make decisions between which AWS services to use, how to deploy various technologies, and what operation aspects you need to focus on. It a battle-proven decision making tool written with input from AWS teams around the world.
* I teach a course on the Well-Architected Framework for A Cloud Guru. Check it out if you're interested in learning how to effectively apply the framework to your builds.
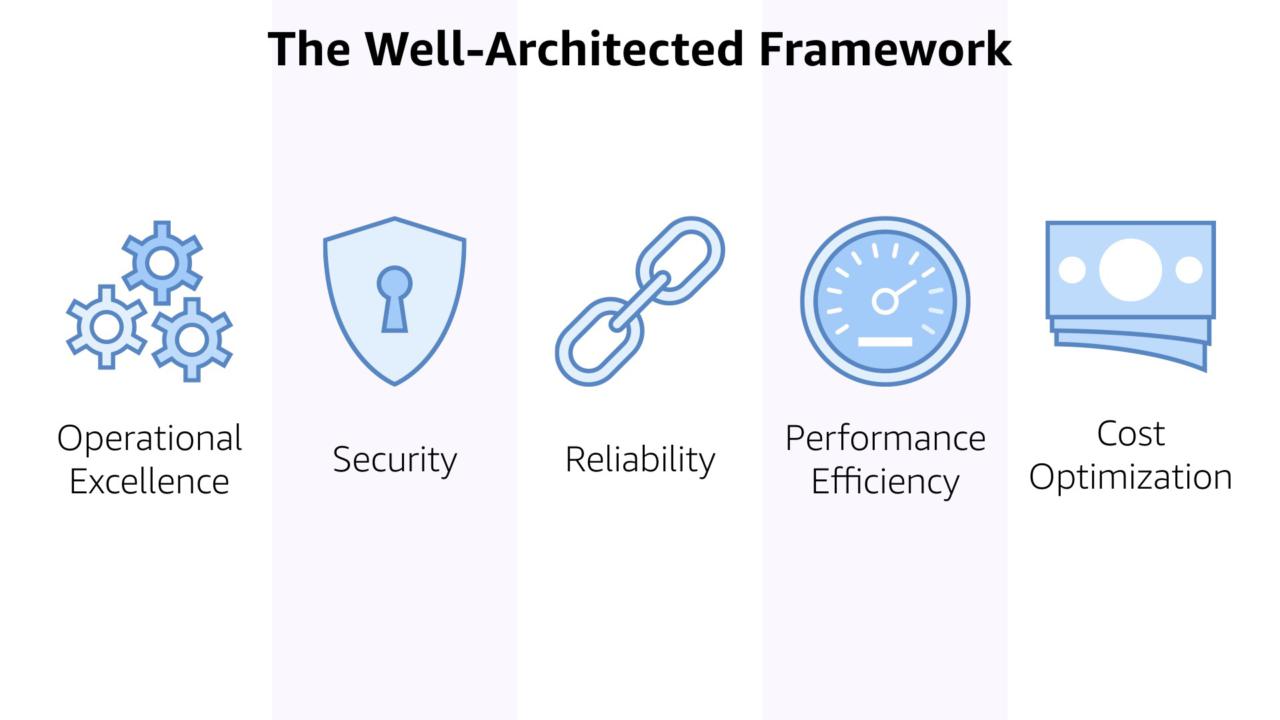
Security is one of the five pillars of the framework. It not off on it's own but part of everything that you do in the AWS Cloud. That's a critical way of thinking of security and (sadly) not one that's often used.

Mainly because people think that cybersecurity is crazy complicated. In fact, most practioners make it far more complicated than it needs to be.
Cybersecurity can be simple. That's what we're going to do in the rest of this presentation.

We're going to take some rather advanced and complex concepts and automate them in a very simple and effective manner.

Restricting permissions in your build

A core security tenant: the principle of least privilege.
Simply put, users and entities should only have the permissions they need to accomplish a task and no more.
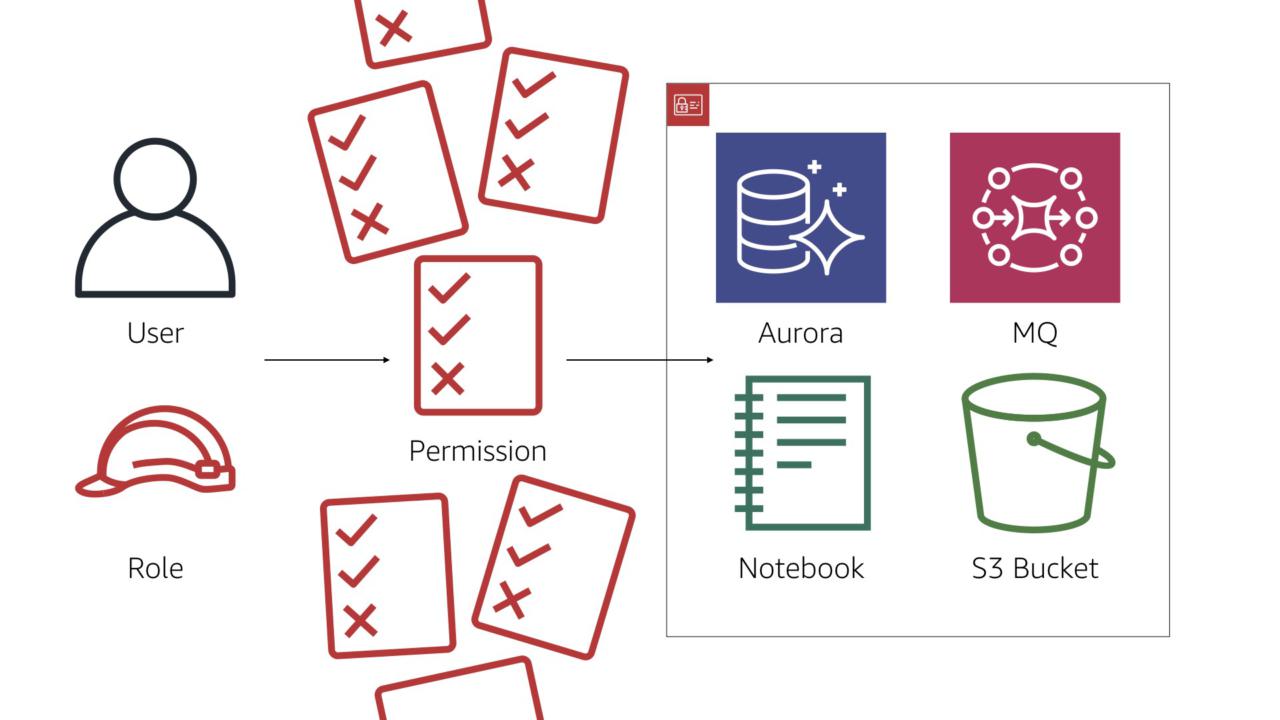
But that's rarely the case. More often than not, a lot of extra permissions are assigned. Often in the name of "making it work" with promises of "we'll clean it up later"...
#protip: later never comes.
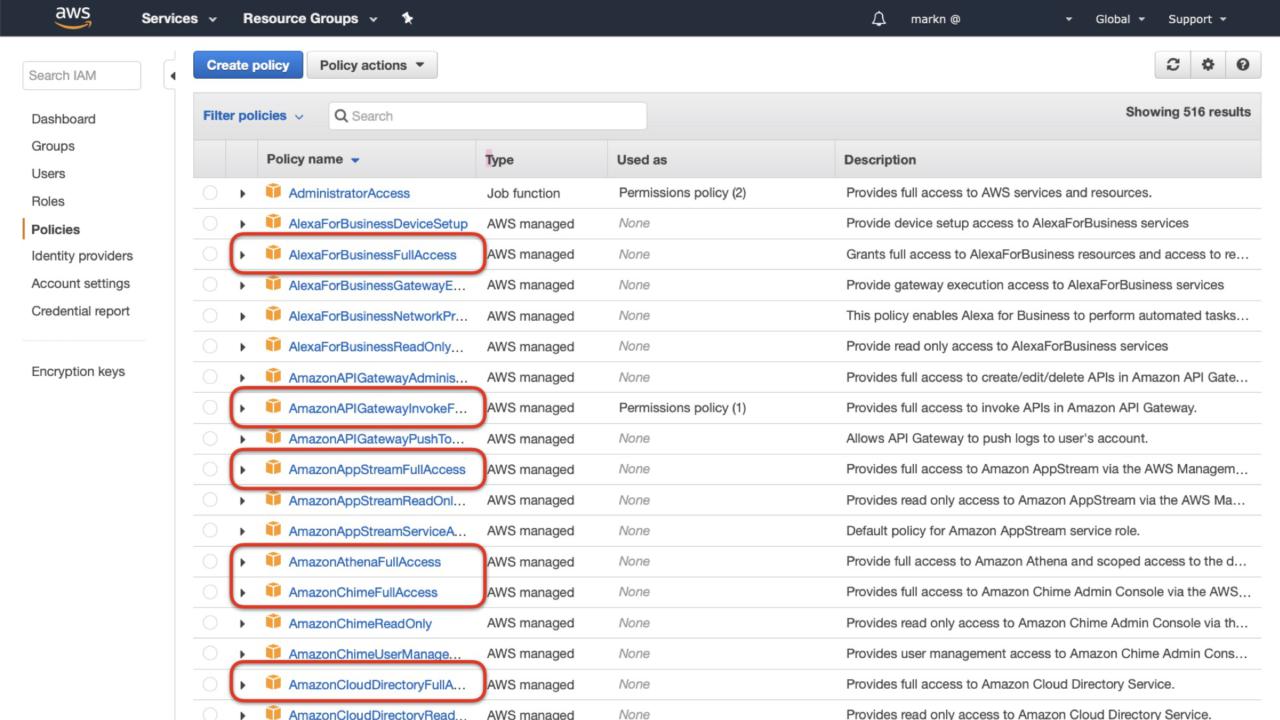
AWS doesn't make it easy to stick to the principle of least privilege. Despite my best efforts with the team, IAM continues to offer "FullAccess" policies.
While the user experience makes sense, this usually causes some serious security issues.
#protip: 99% of the time you see these policies used in production, it's wrong. Way, way too many permissions for most tasks.

The steps to automate a solution:
- In an isolated test environment, apply a FullAccess policy or the permissions you believe are required
- Complete the desired tasks
- Compare against CloudTrail logs to verify actual permissions used
- Use new policy to enforce the principle of least privilege
- Repeat as code changes
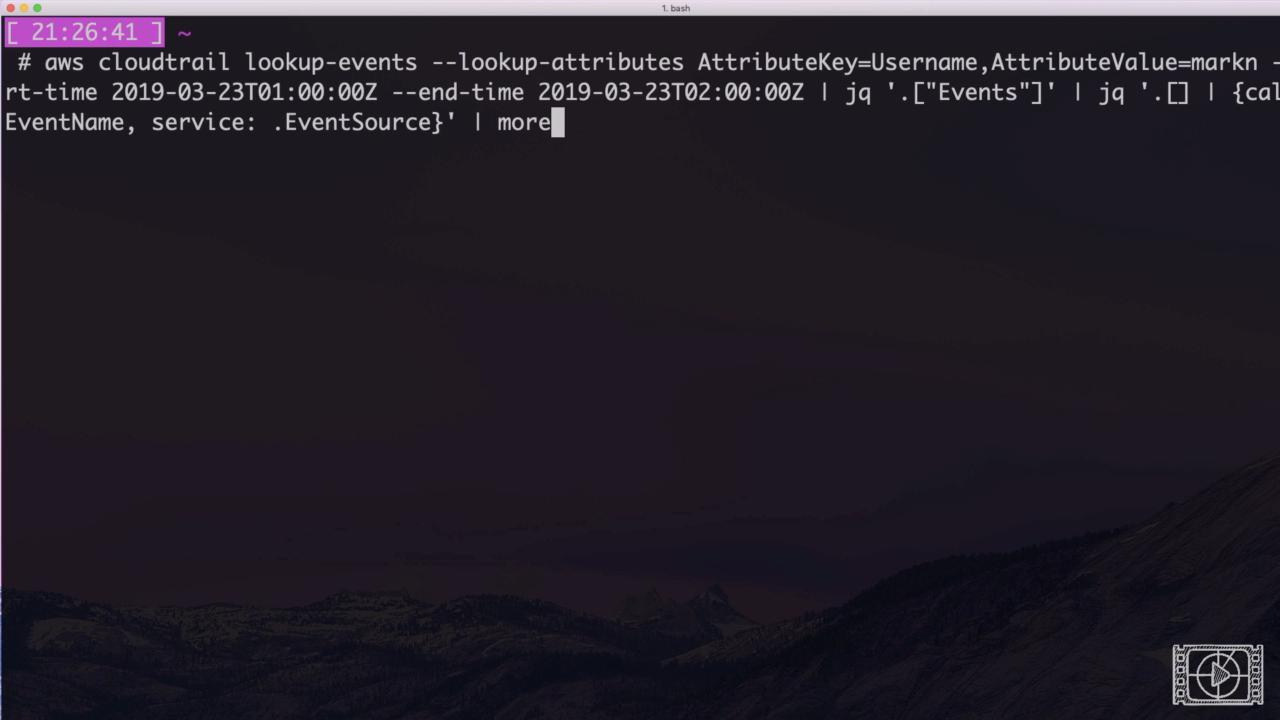
Believe it or not, a simple(ish) console command will solve this.
aws cloudtrail lookup-events --lookup-attributes AttributeKey=Username,AttributeValue=USERNAME --start-time 2019-10-03T01:00:00Z --end-time 2019-10-03T02:00:00Z | jq '.["Events"]' | jq '.[] | {call: .EventName, service: .EventSource}' | more
This generates a clean list of the service endpoints called during the specified timeframe.
This command uses the AWS CLI to call the CloudTrail service, specifically the 'lookup-events' endpoint.
We use this command to return the audit log entries for our testing period. The command offers a number of ways to filter out irrelevant information.
We then pass the results of that AWS CLI command to a very handy tool called, "jq".
This tool helps search JSON data and pull out values of interest. The syntax takes a little getting used to but it's immensely powerful.
With this simple two step process, we've automated a simple verification of what permissions are actually being used.
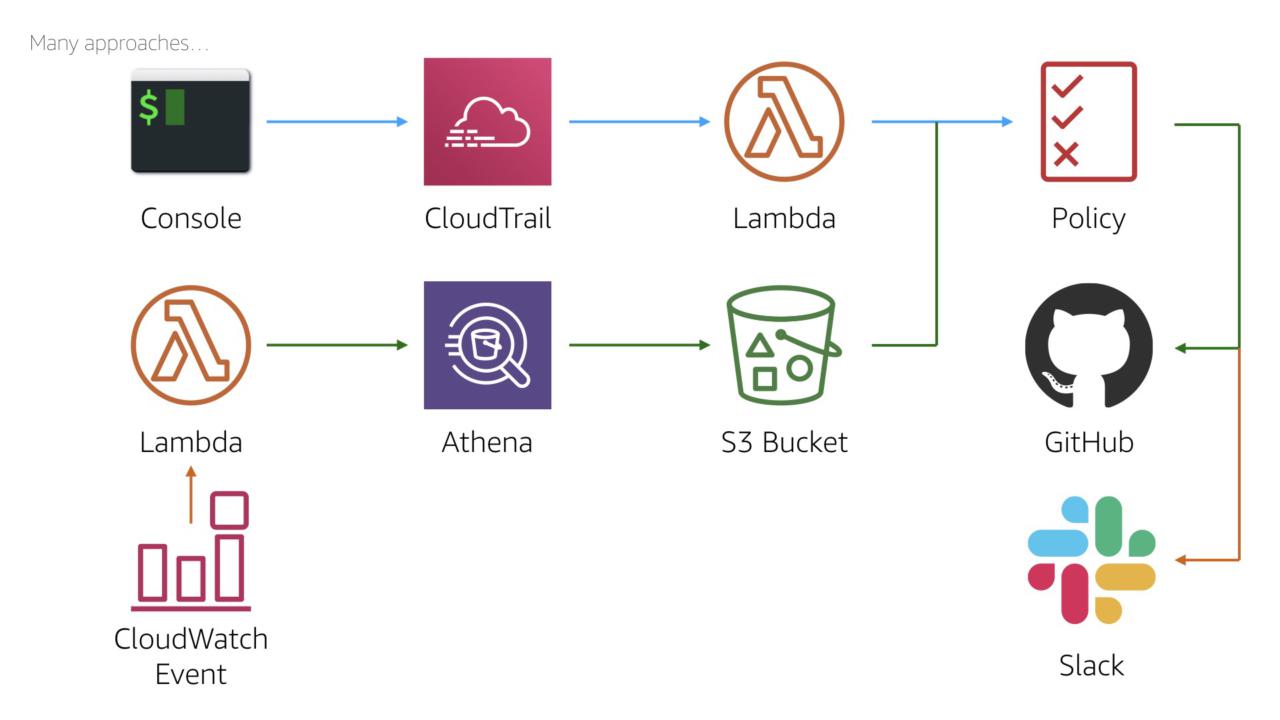
As with anything in the AWS Cloud, there's at least six ways to solve any problem. We can expand this process to automatically apply the policy.
We could run the query as a 'cron' job using a scheduled CloudWatch Event or we could use a lambda triggered from a build server.
Similarly for the output, we could not only apply the policy but we could add it to the code repository. We could even send a message to the team's Slack channel.

Monitor S3 Exposure

One of my pet principles that should be obvious...
The principle of the face palm: do not make that which is secure, insecure.
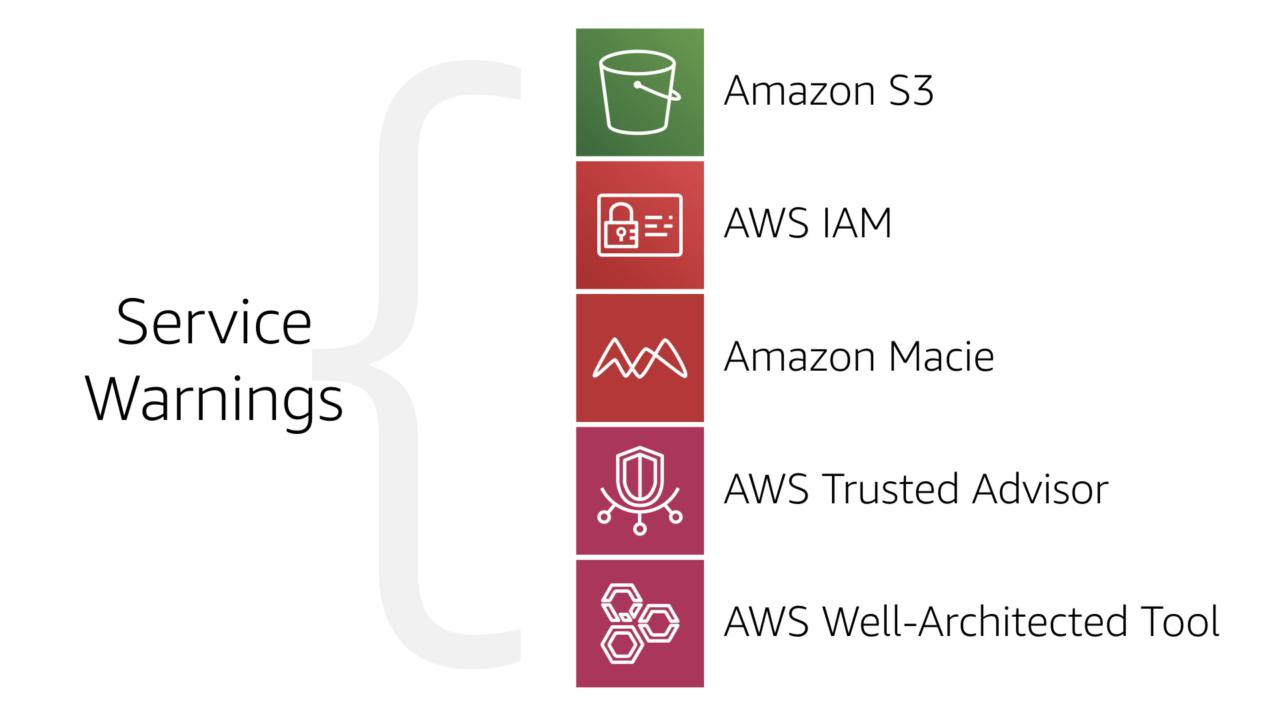
AWS does it's best to help builders and stop them to mistakenly exposing their data from Amazon S3.
All of these services have one or more ways to warn users when an Amazon S3 bucket is set to allow public access. But since access is your responsibility, the buck stops with you (as it were).
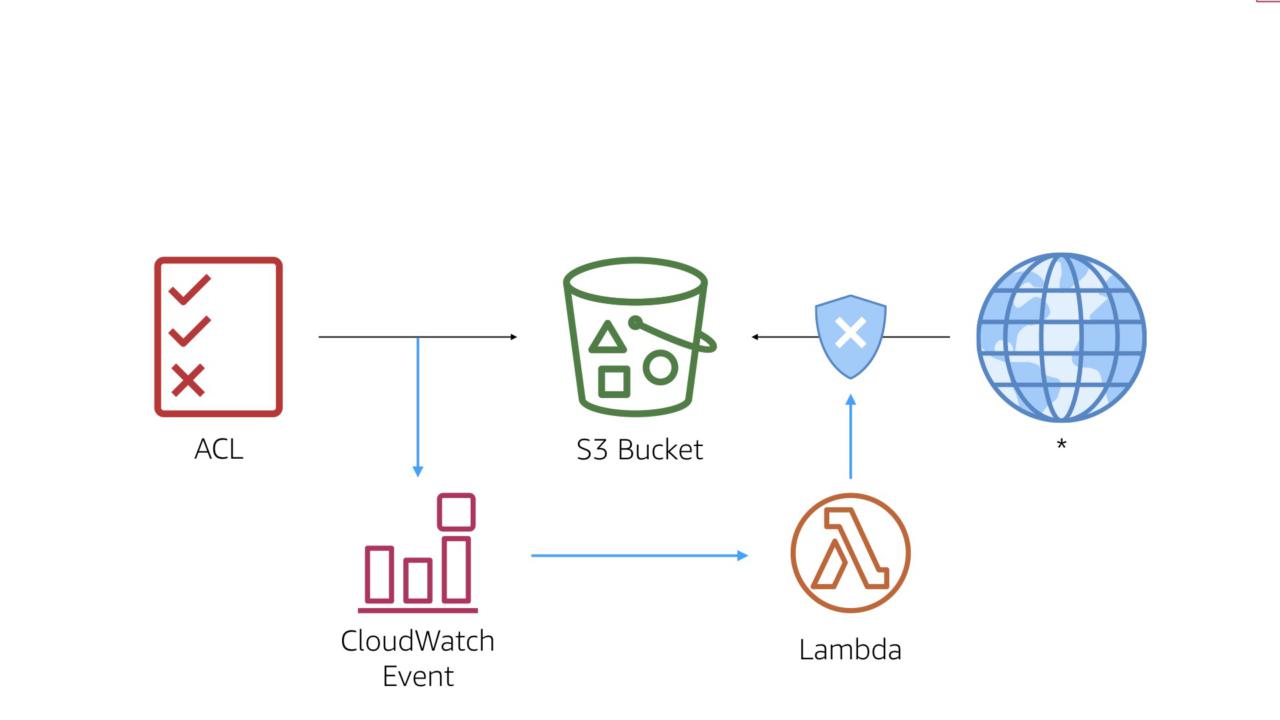
The workflow is simple. When a permissions change is made that applies to the target bucket, we hook the appropriate CloudWatch Event in order to trigger a custom AWS Lambda function.
We'll hook the PUT bucket policy event.
You should also several IAM events in order to get full coverage. For simplicity, we'll stick with the one event here.

Track Production Logins

A core principle of the DevOps movement is that systems, not users access productions systems.
This ensures consistent configurations and reduces the possibilities of an error.
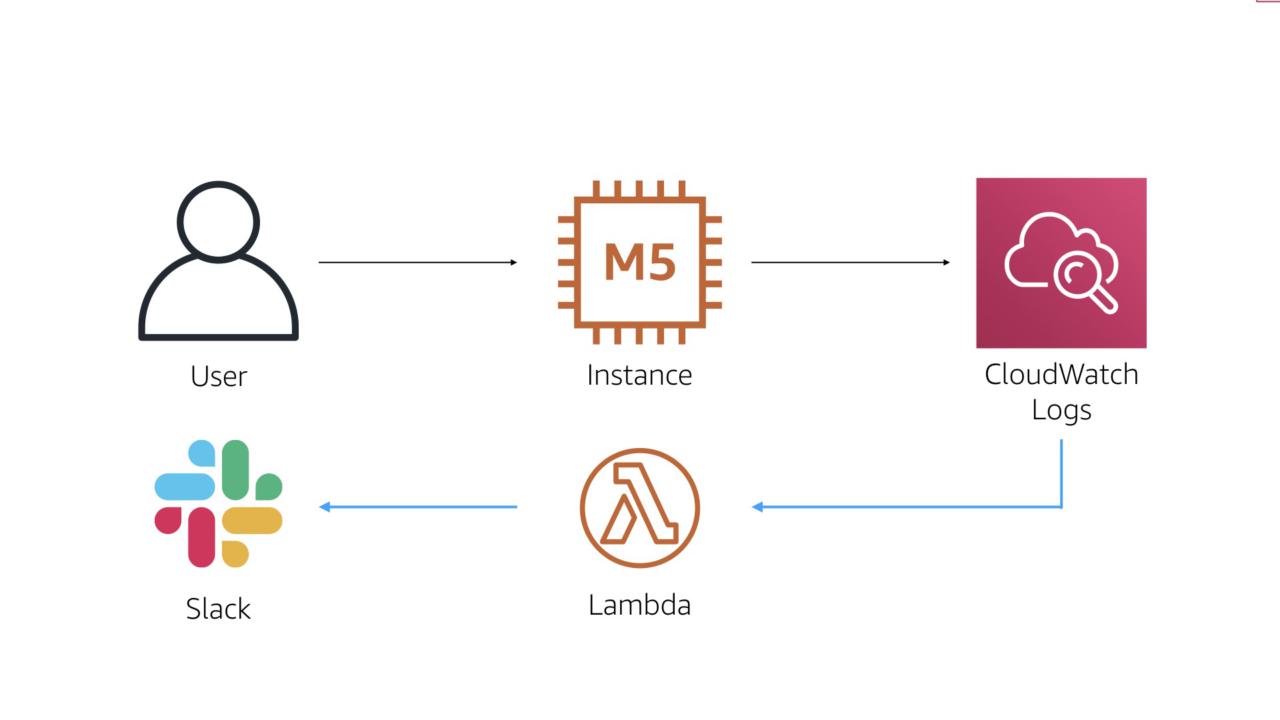
The work flow for this process is also straightforward. We'll use CloudWatch Logs to monitor system events such as an RDP or SSH login.

Once we see one of those events, we'll trigger an AWS Lambda function. That function then sends a message to the team's Slack channel.
#protip I met an organization that was using this workflow and actually prompting users in Slack to verify is they were logging into a system. If the user said yes, they were prompted with some education info. If they said no, a security incident was immediately raised.

Forensic Isolation

Another made-up-but-makes-sense principle...
The Crichton principle: if something unknown is happening, quarantine it until you figure it out.
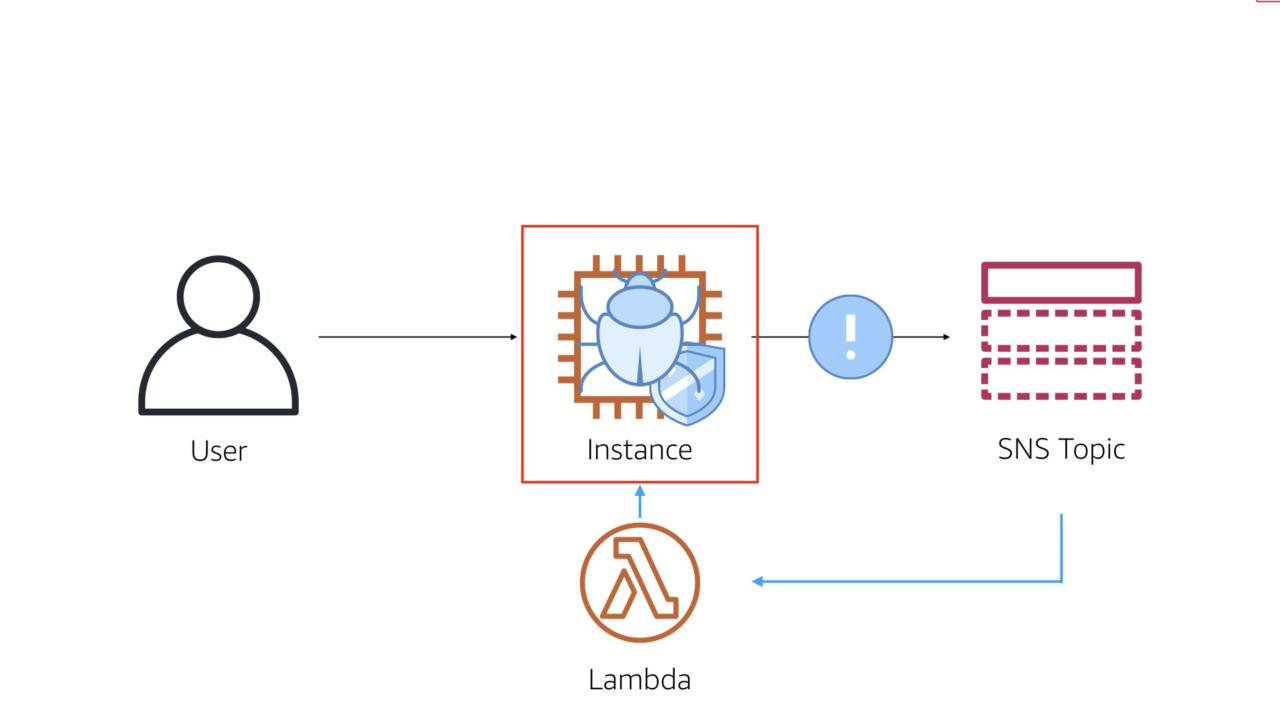
The workflow here is simple and straightforward. In order for this to work, you'll need a security tool (open source, commercial, or home grown) that can emit events to something like Amazon SNS.

- Security controls on the instance alert on issue
- Lambda triggers by alert
- Change the security group to make the system inaccessible
- Open security incident
- Create a forensic instance to analyze the infected instance
The trick to this work flow is an Auto Scaling group. For cloud-native workloads, this is a normal feature.
But even for legacy workloads, the Auto Scaling group can help when you set the minimum and maximum to one. This ensures that there is always one server running.
When you change the security group to be inaccessible, the Auto Scaling health checks fails and the system spins up a new instance.
Best case scenario, this takes care of the attack and you have an instance to analyze at your leisure.
In the case of a persistent attacker, this work flow automatically keeps them at bay by destroying their foothold every time compromise the instance.

What's Next?

A few ideas of work flows you can implement yourself...
- Send custom application logs to AWS Config (via rules) for a central compliance log
- Correlate Auto Scaling alerts with backend data to detect possible DDos attacks
- Detect unauthorized drift from applications and infrastructure using CloudFormation templates
- Streamline the incident response process, including restoring to full capacity
- Automatically find and mitigate vulnerabilities before deployment

Bottom line: don't over complicate security!

There are three generic steps to automating any activity:
- Start manually
- Determine your risk tolerance
- Lambda all the things
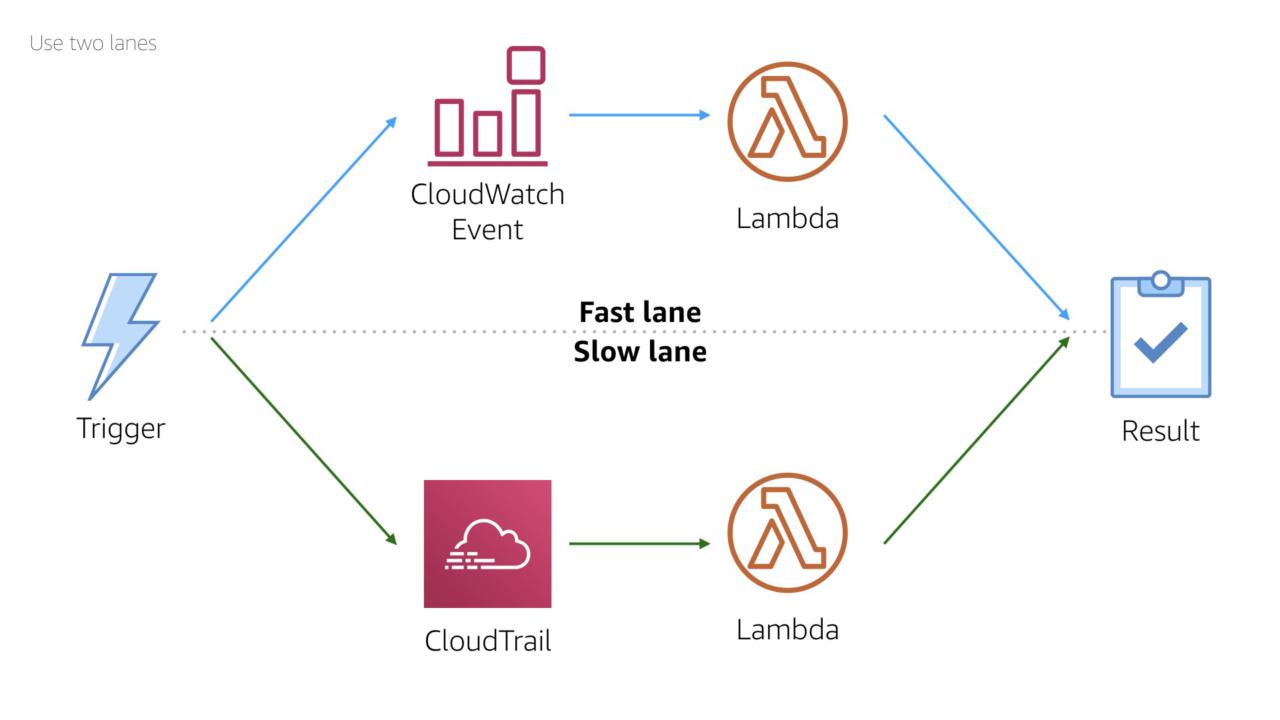
An important caveat: be aware of how fast your event source is.
CloudWatch Events trigger in near real time. This makes the service ideal for response work flows.
In contrast, CloudTrail usually delivers logs in 2-4 minutes after an event occurs. There's no guaranteed delivery time, so this is a simple rule of thumb.
This timing makes CloudTrail ideal for compliance and clean up work flows.

Remember the goal of cybersecurity: to make sure that whatever you are building works as intended...and only as intended!

Thank you!