This talk (DOP284-S) was presented at AWS re:Invent 2020 and is now available to watch on-demand.
There’s always more than one way to solve a problem. That’s a big advantage of AWS, but it can also be overwhelming to deal with. Is Amazon Aurora the right choice? MySQL on Amazon RDS? Create your own on Amazon EC2?
These are just some of the decisions that your team is going to have to make. You may make mistakes. Decisions you make now could cause problems down the road. This session explores how teams handle failure and come back stronger, using resources like the AWS Well-Architected Framework, Amazon CloudWatch, and many more tools to help make decisions and build better.
Slides

Everyone is going to make mistakes. It's going to happen. The real question is whether it was a mistake that you should have been able to plan for...and thus avoid. Or was it a mistake that was so out there that there was no way the team could've ever planned for it? So how do you avoid avoidable mistakes?
Typically, you'll seek out "best practices" These hallowed commandments from those that have tread your path before you. Actions that have been proven through their user by other teams...

I can't stand "best practices" The reason? Because the environment in which they've been proven out probably doesn't match yours. Best practices lack context.
Yes, they may work and work in wide variety of situations but more often than not, they lock you into one way of thinking. One way of solving a problem set. Best practices are useless, I just like looking at and teaching first principles instead.
"Why" we take a specific approach in a context with certain attributes
Which leads us to the AWS Well-Architected Framework. It's often thought of as a collection of best practices. And while it does include some best practices, it's primarily a framework for getting your team to think about delivering solutions in a modern way.
It's not just about turning a particular feature on, but how that fits into your larger strategy in order to reach your desired outcomes
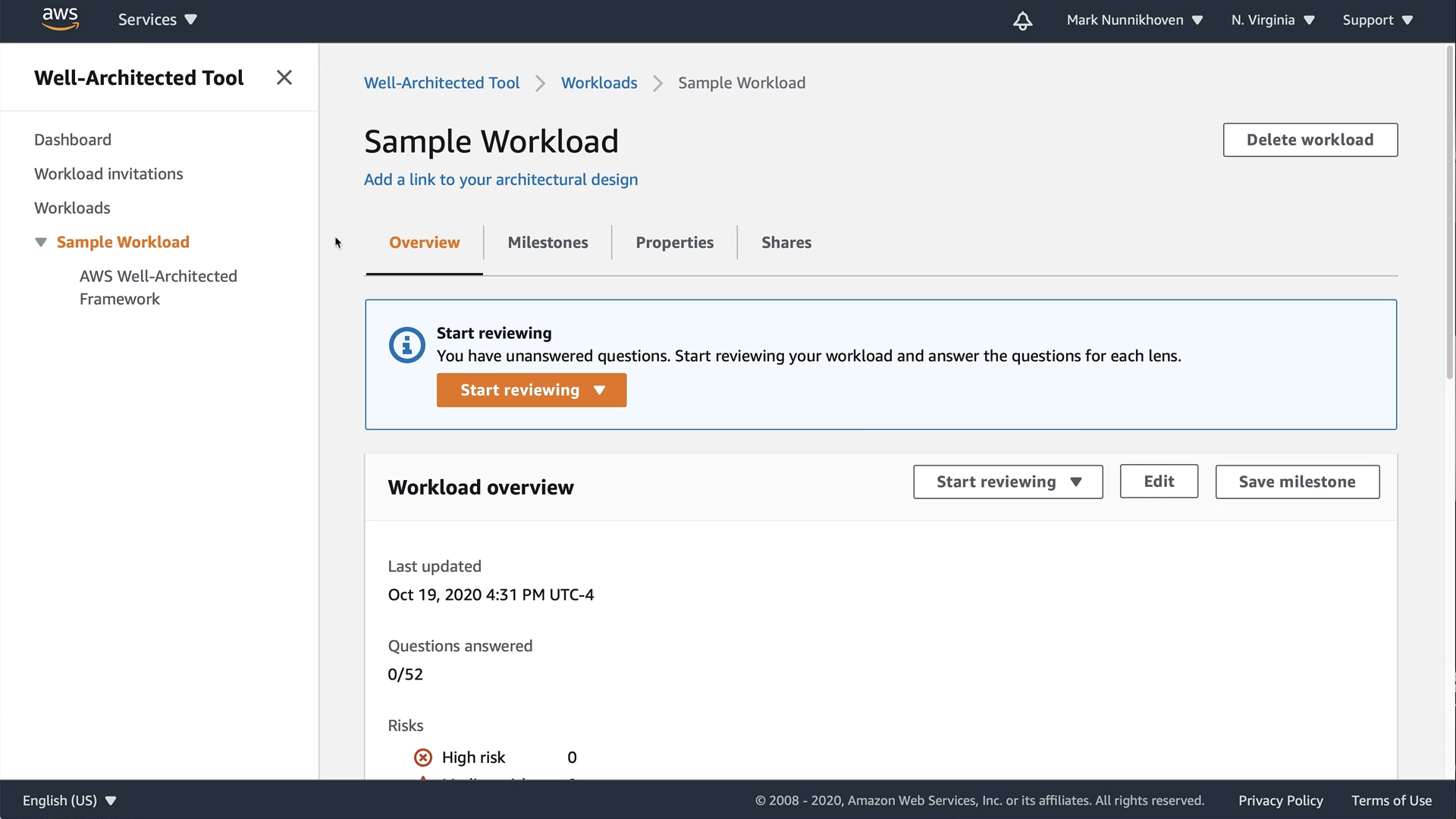
Here's a quick look at the AWS Well-Architected Tool. It's a service from AWS that helps you organize the questions and answers your team works through during a Well-Architected Review.
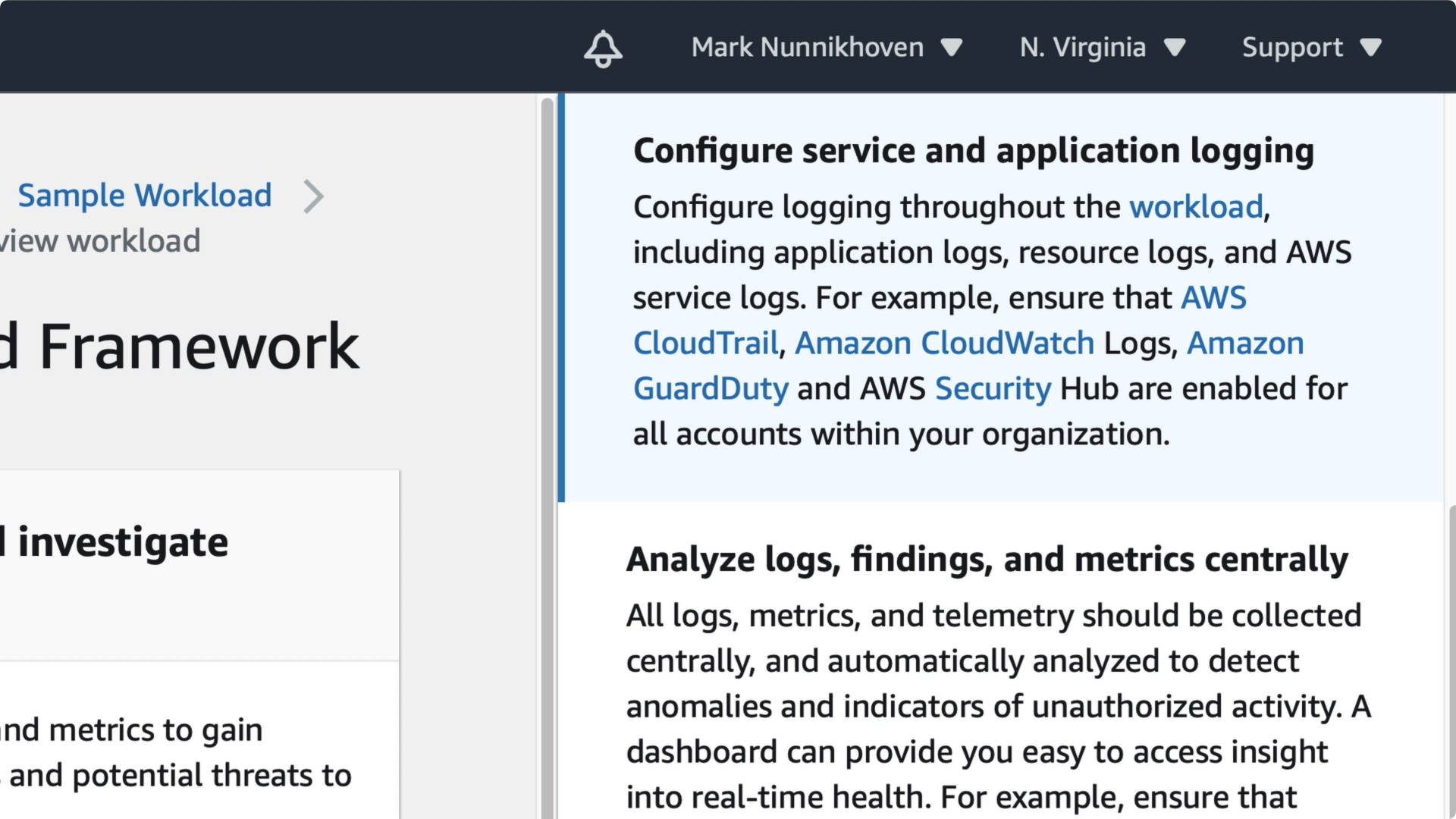
Question SEC-04, provides something that looks an awful lot like a "best practice"
Turn on AWS CloudTrail, Amazon CloudWatch Logs, Amazon GuardDuty, and AWS Security Hub for all accounts in your organizations.
That's solid advice and your should do that using AWS Organizations.
But...
What are you going to do if Amazon CloudWatch Logs triggers an alert? Or if AWS Security Hub raises a finding?
The "best practice" is simply turning these things on isn't the end of the story. There's a lot more work that needs to be done...mainly mapping out how your team will respond to this information
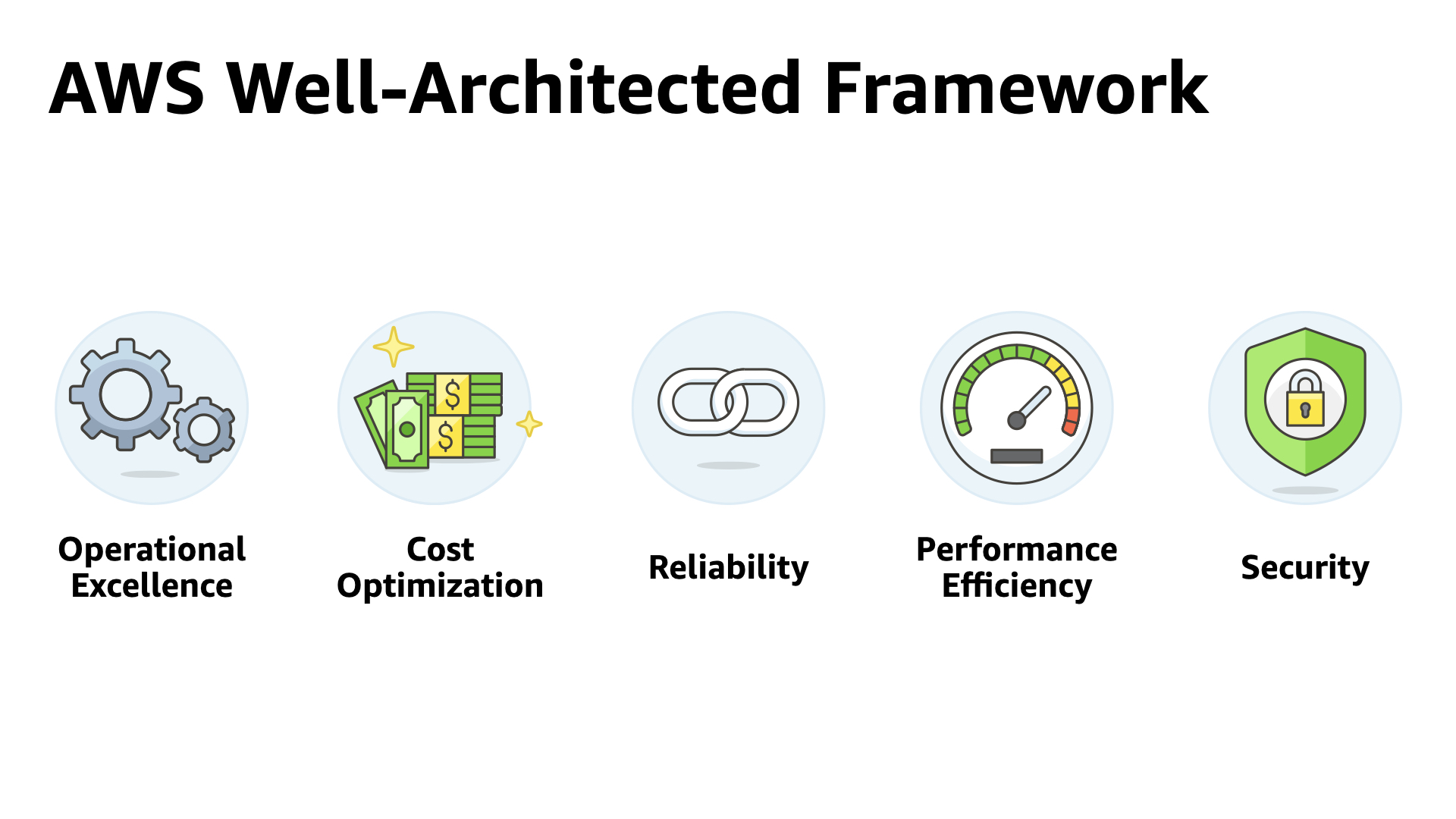
The framework itself is structured around five pillars;

More importantly, the framework emphasizes six principles;
- Use on-demand resources whenever possible
- Automate all the things
- Test regularly and at scale
- Fact-based feedback loops
- Evolve architectures
- Practice, practice, practice

Before we dive into some stories to illustrate how to use the framework...remember no judgements.
The stories I'm about to present are real and the teams made logical choices given their knowledge and constraints at the time.
One of the goals of the framework it to help you use data to iterate and evolve your architectures. You can best accomplish that with blameless reviews and no judging people in a situation you weren't involved it.
This is also a core tenet in The Phoenix Project and The Unicorn Project which also advocate a modern approach to building solutions

The first example is a team that built a custom video streaming platform.
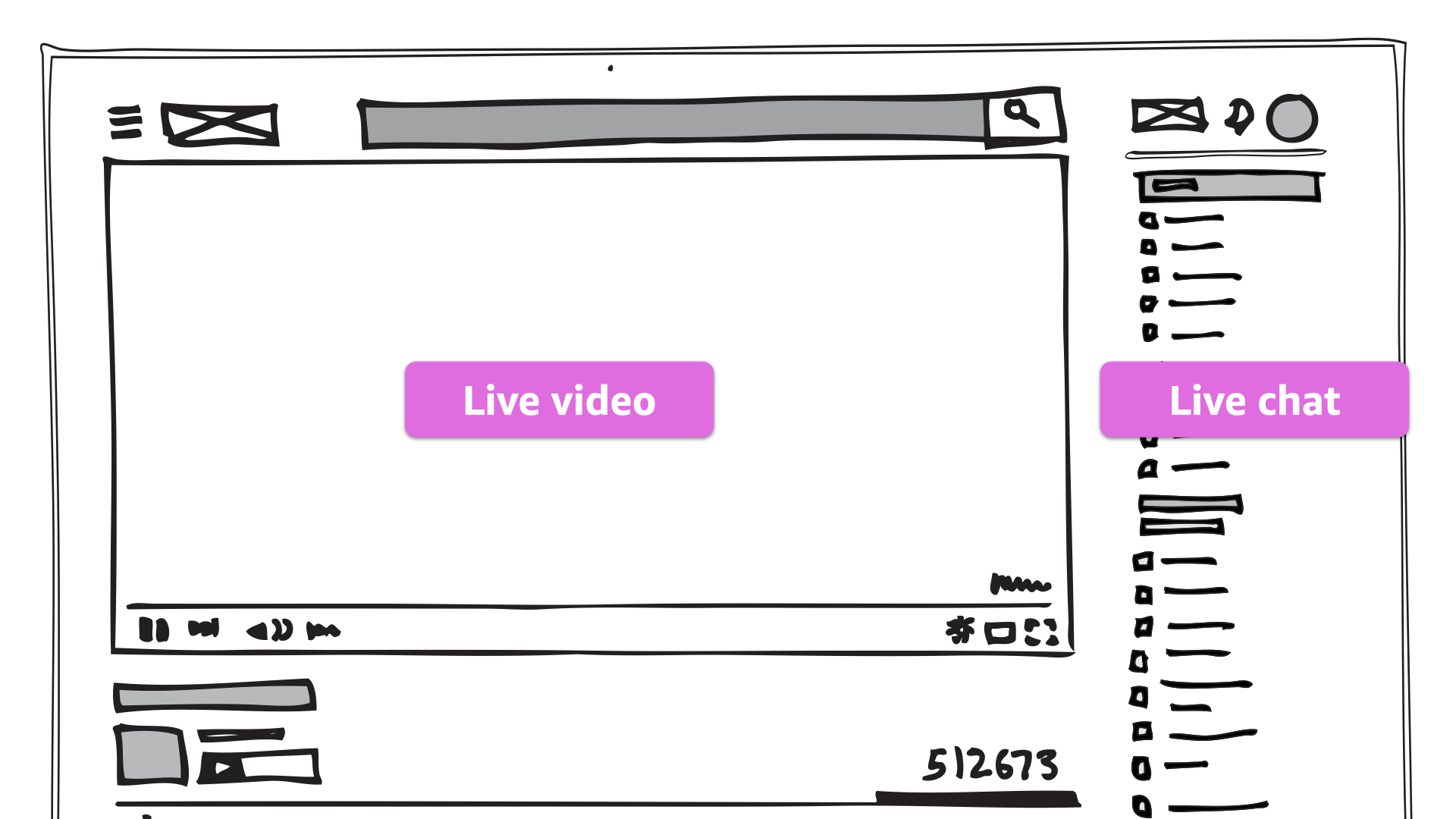
Their goal was to meet the increased need for streaming content in a specific niche. They wanted to deliver something with a common and intuitive feel for the user.
No surprise in the UI here. No need to reinvent the wheel
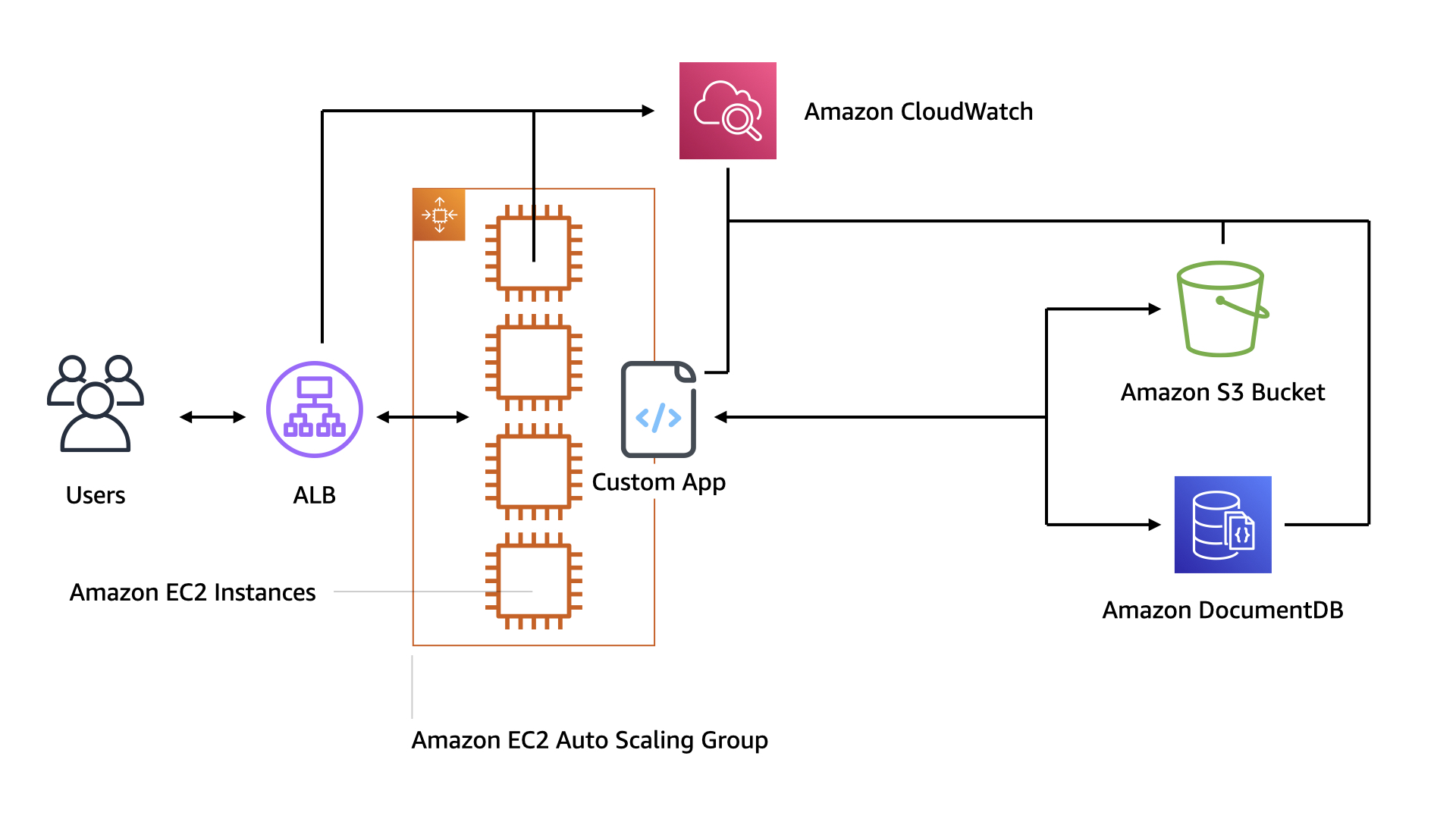
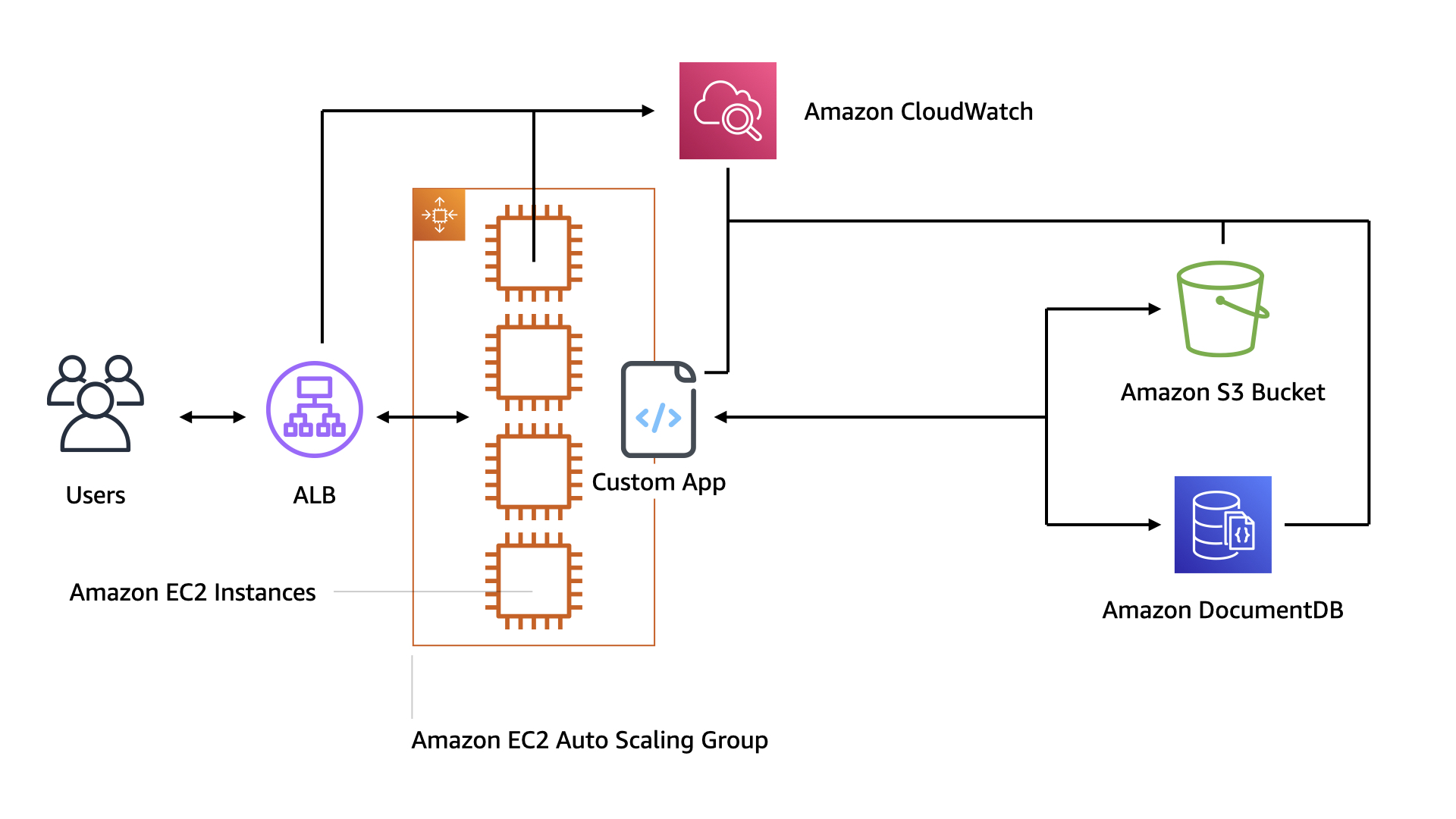
This is the initial architecture. It started out as a proof of concept that ended up sliding into production. That happens a lot. It shouldn't, but it does.
The good news is that it's very simple and there's not much operational overhead.
Users hit an ALB which routes to an EC2 AutoScaling Group. The instances in that group are running the custom applications which leverages both Amazon DocumentDB and Amazon S3 for data storage
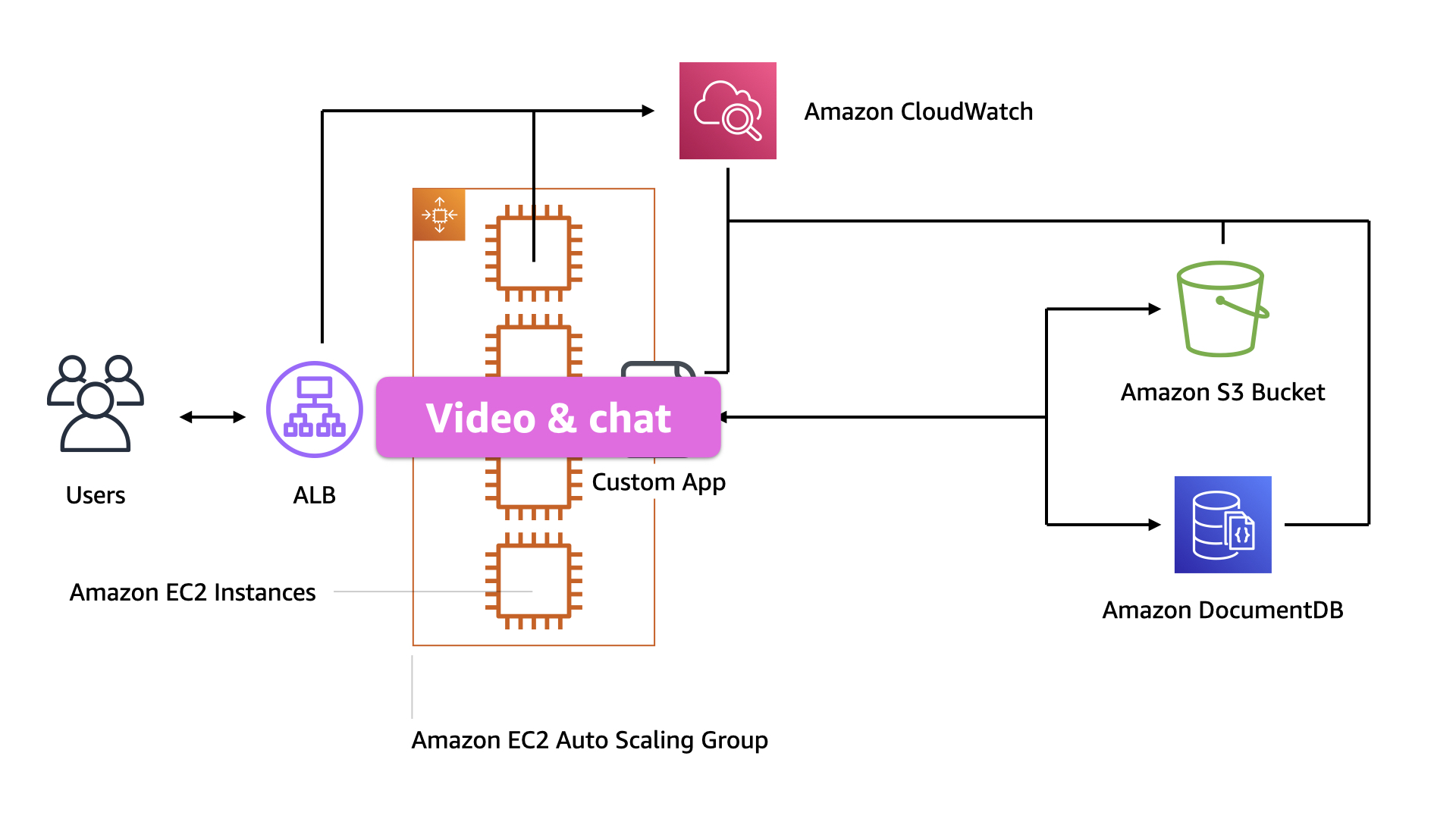
The biggest issue with this design is that everything is running on that pool of EC2 instances. Both the video and chat. The app is one entire blast radius
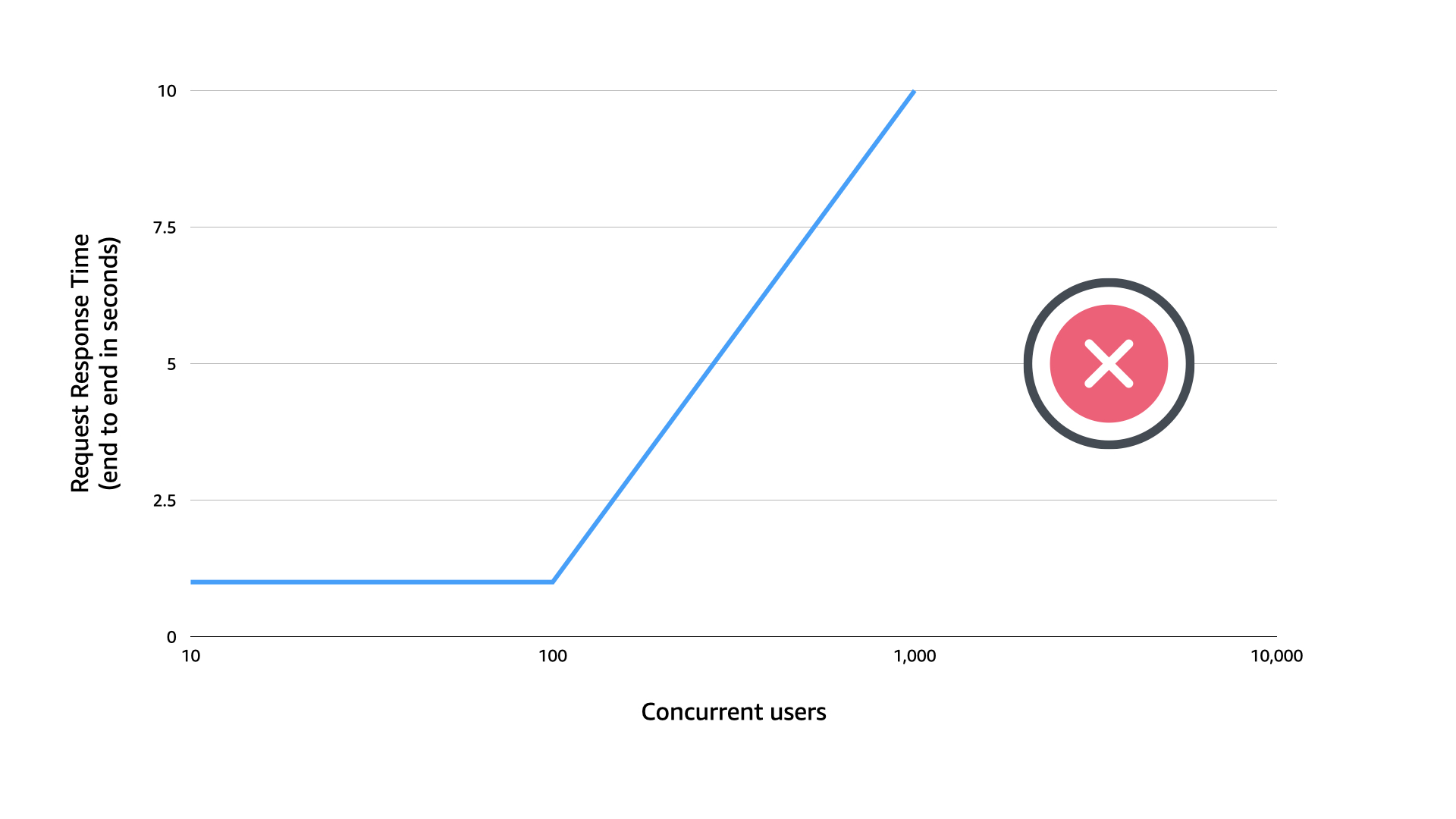
The team ran tests but not at scale. The first stream they hosted was a huge success...in that they sold a lot of tickets. This pushed concurrent users well beyond what was tested.
Of course—Murphy's law in full effect—as the number of concurrent users leapt over 100 (near their testing limit), the system started to slow down.
Eventually delivering response times close to 10 seconds, at which point users started dropping off the streams and retrying. This created a weird autoscaling loop where instances were spinning up and down trying to figure out and meet demand.
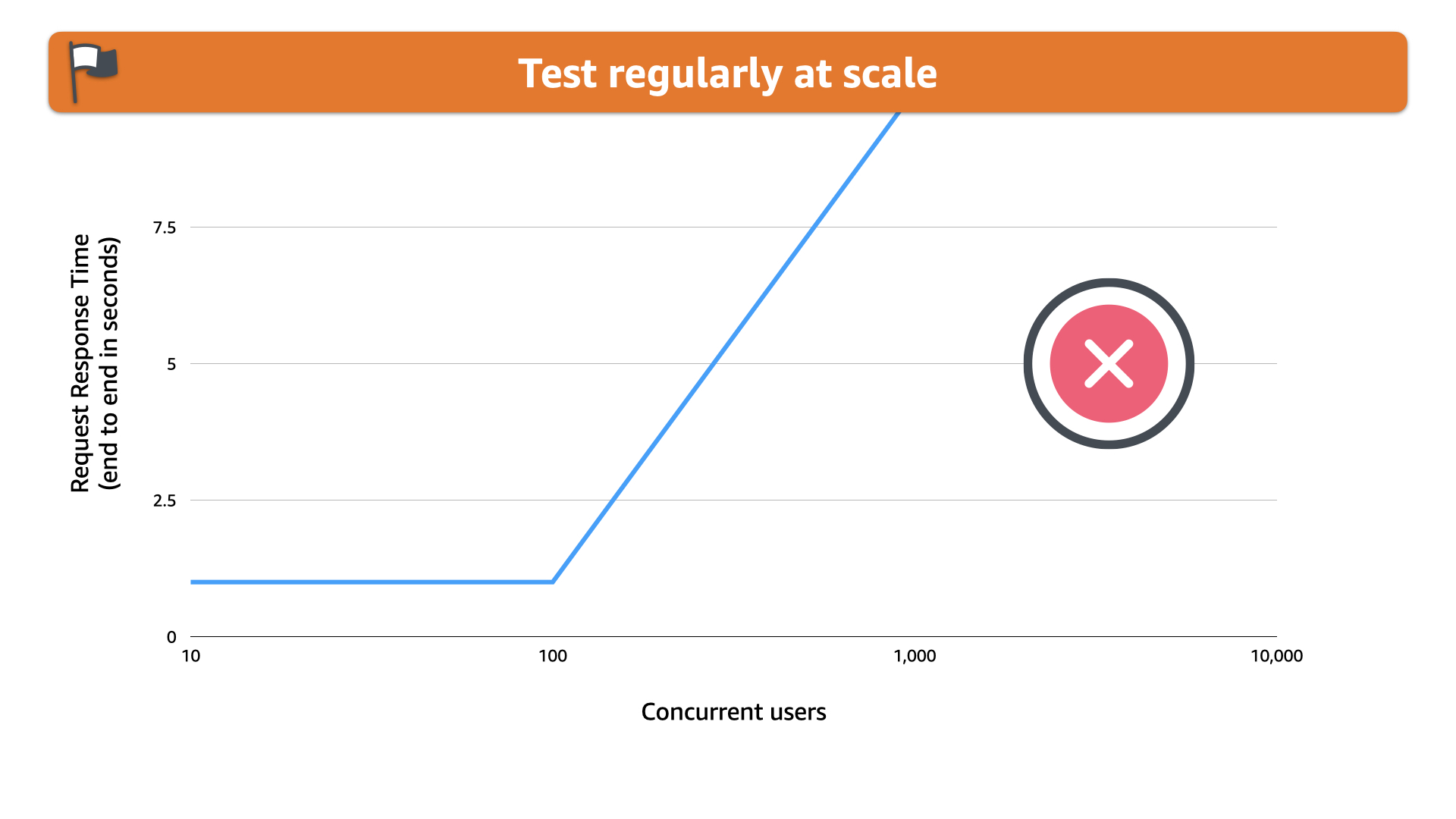
If the team had tested at scale. They would seen this scaling issue.
The "easy" solution would have been to pre-scale at that of the event and remove instances from the pool if that level of service wasn't required. This would've created a much better user experience.
But the team didn't test at scale. They were satisfied with testing at a small scale which didn't reflect the business reality
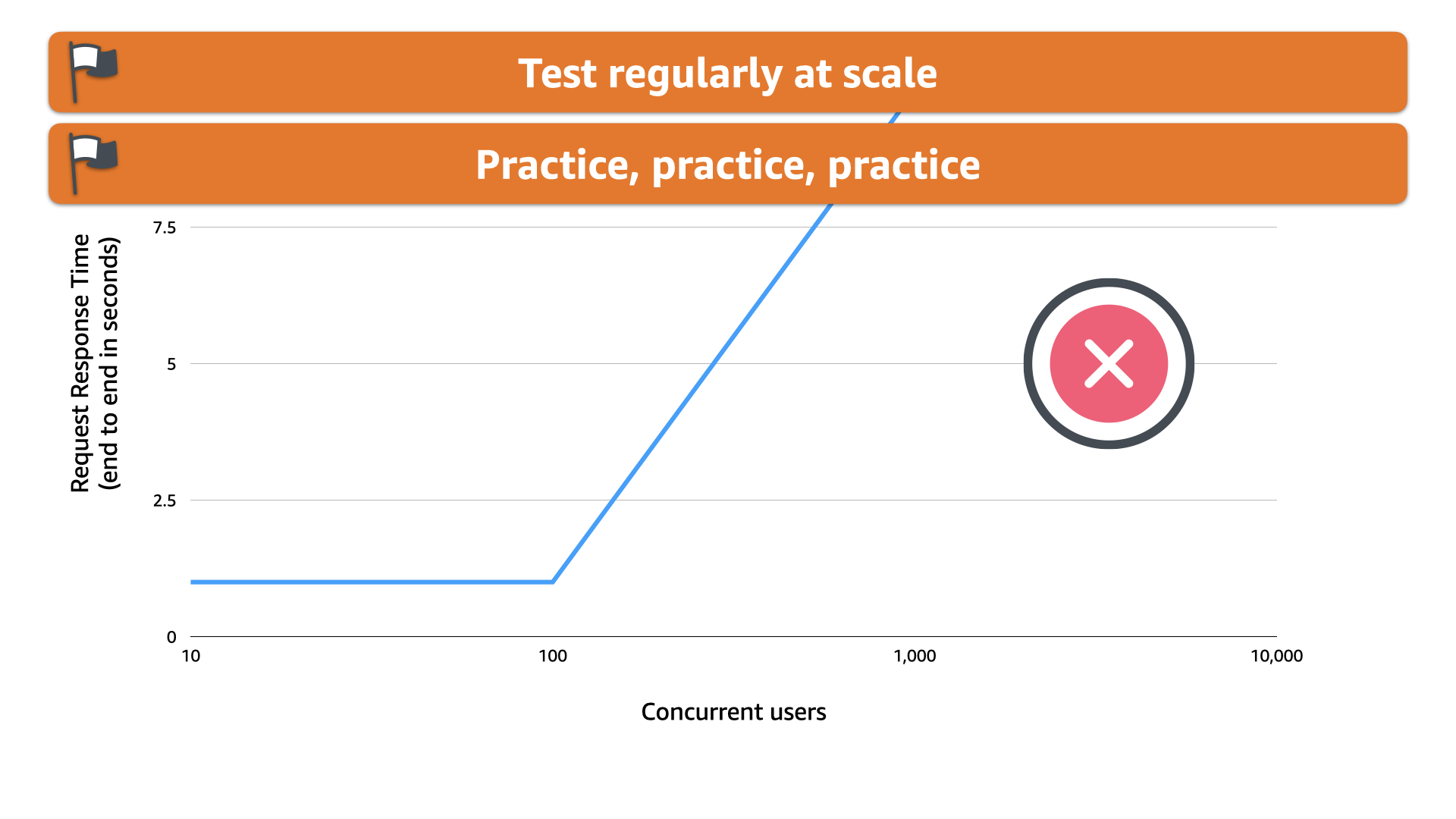
Worse, as the system was crashing and failing to deliver the promised stream, the users were left in the dark!
With the chat and video functionality delivered from the same instances, the users had no way of knowing what was going on.
The team hadn't practiced this type of scenario and was trying to figure out on the fly how to communicate with their paying customers. Not a good look for a new service

If we line up what the team has done so far with the framework, we see that they have had reasonable success with operations, cost, and security...and no success with reliability or performance 😔
Based on that first, disastrous experience, the team decides to make some changes
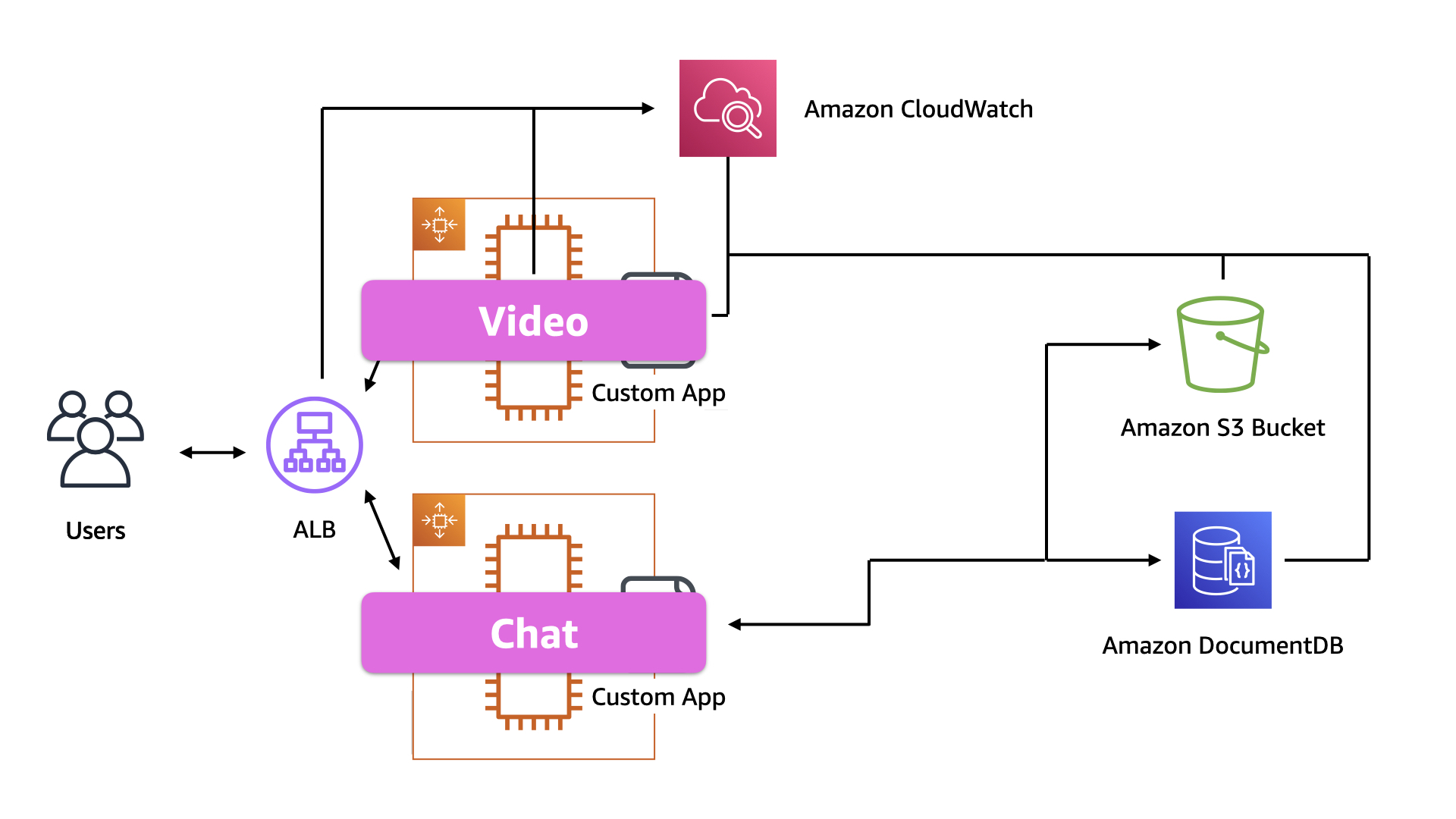
Step #1, they break up the EC2 instances into two pools. One for video and one for chat. They use the ALB to route user requests to the appropriate pool based on the requested URL
The evolution of their architecture address an immediate and pressing problem: communicating during issues. The chat side of this app is much easier to scale and provides an outlet to discuss issues with customers if there are stream problems in the future
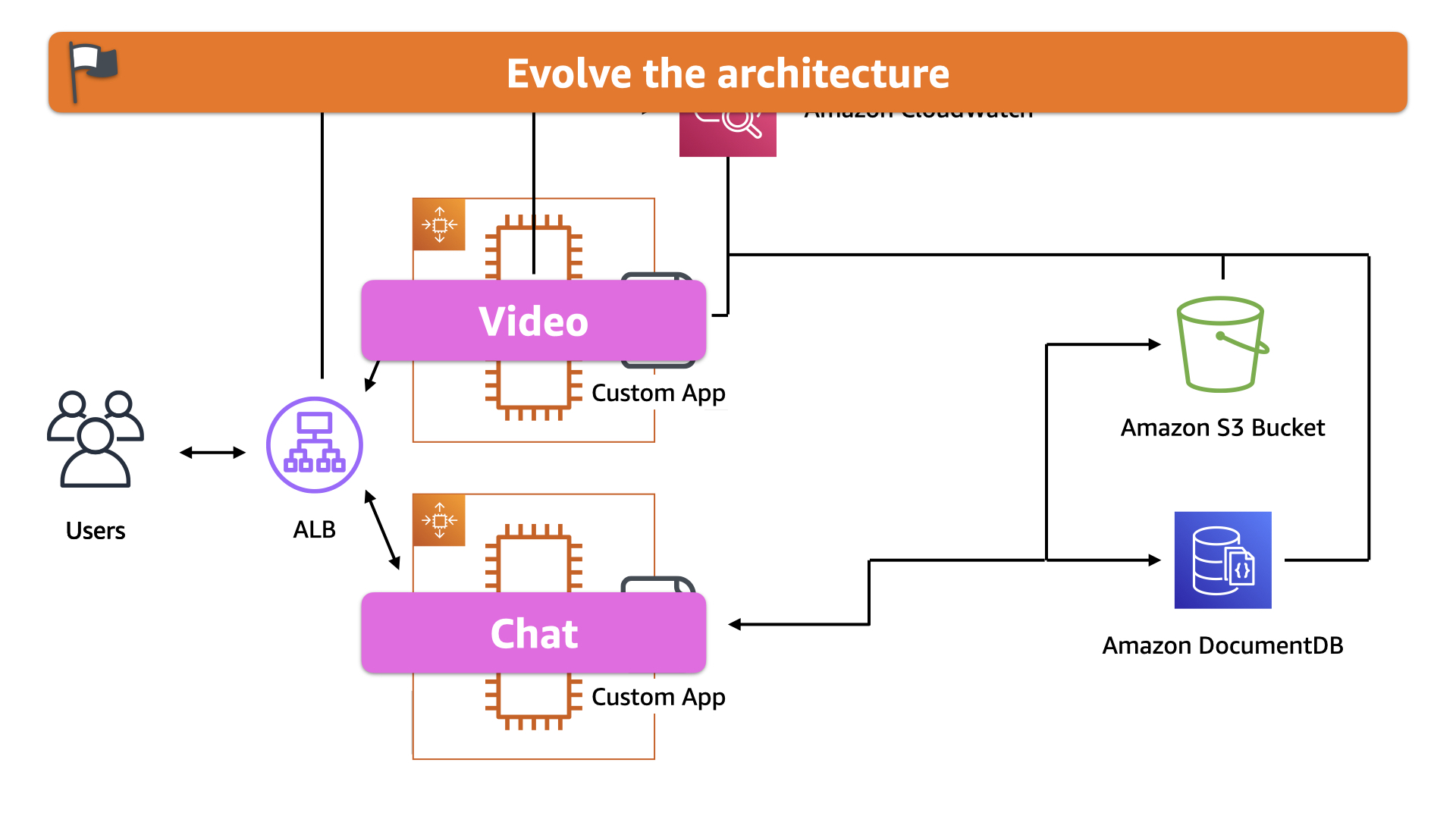
The first evolution leads to another. Once the team separated out the video streaming portion to a unique instance pool, they asked, "Can we make this simpler?"
Yes, yes they could.
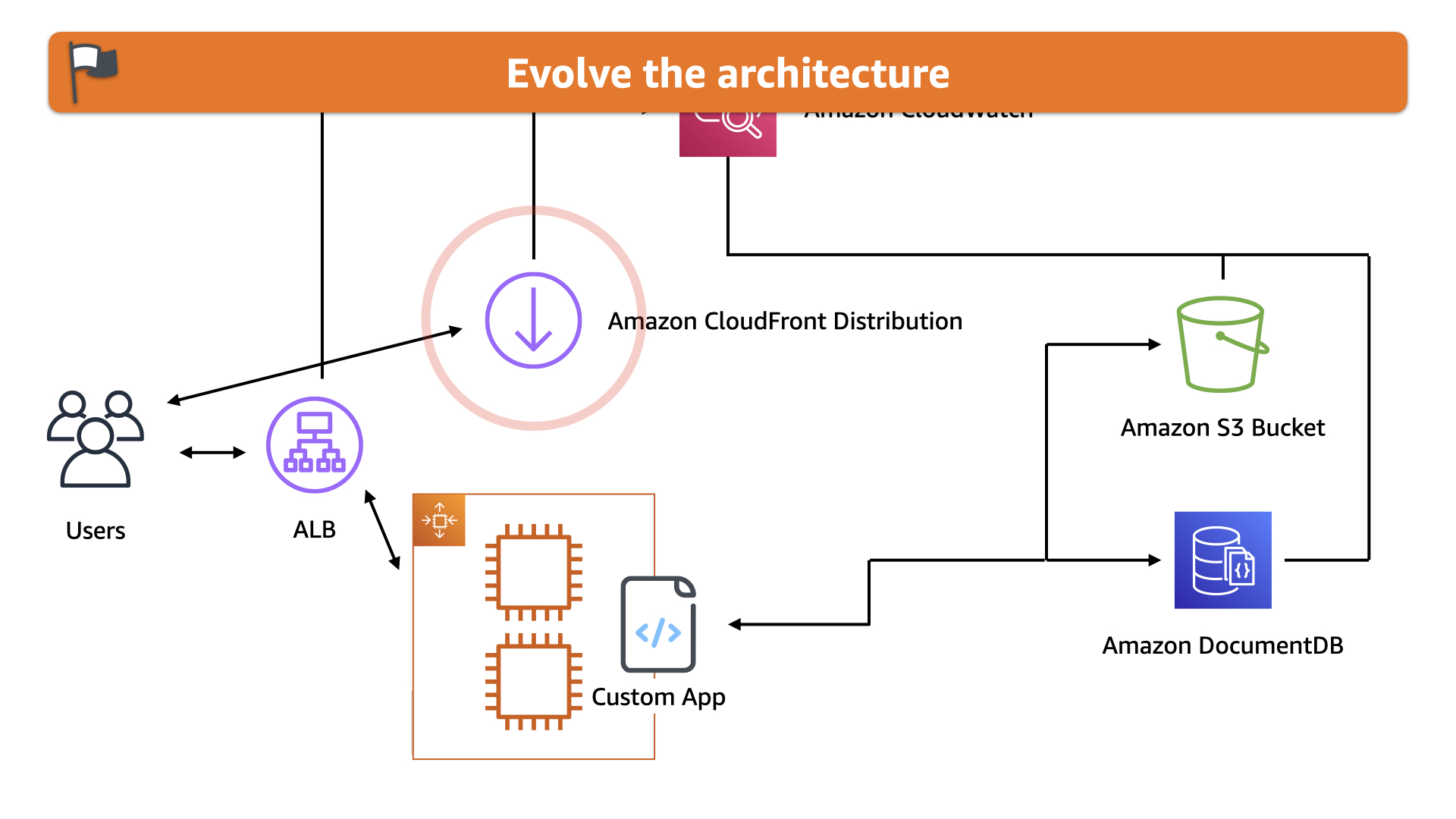
They leveraged the streaming capabilities in the Amazon CloudFront to deliver the video to their customers.
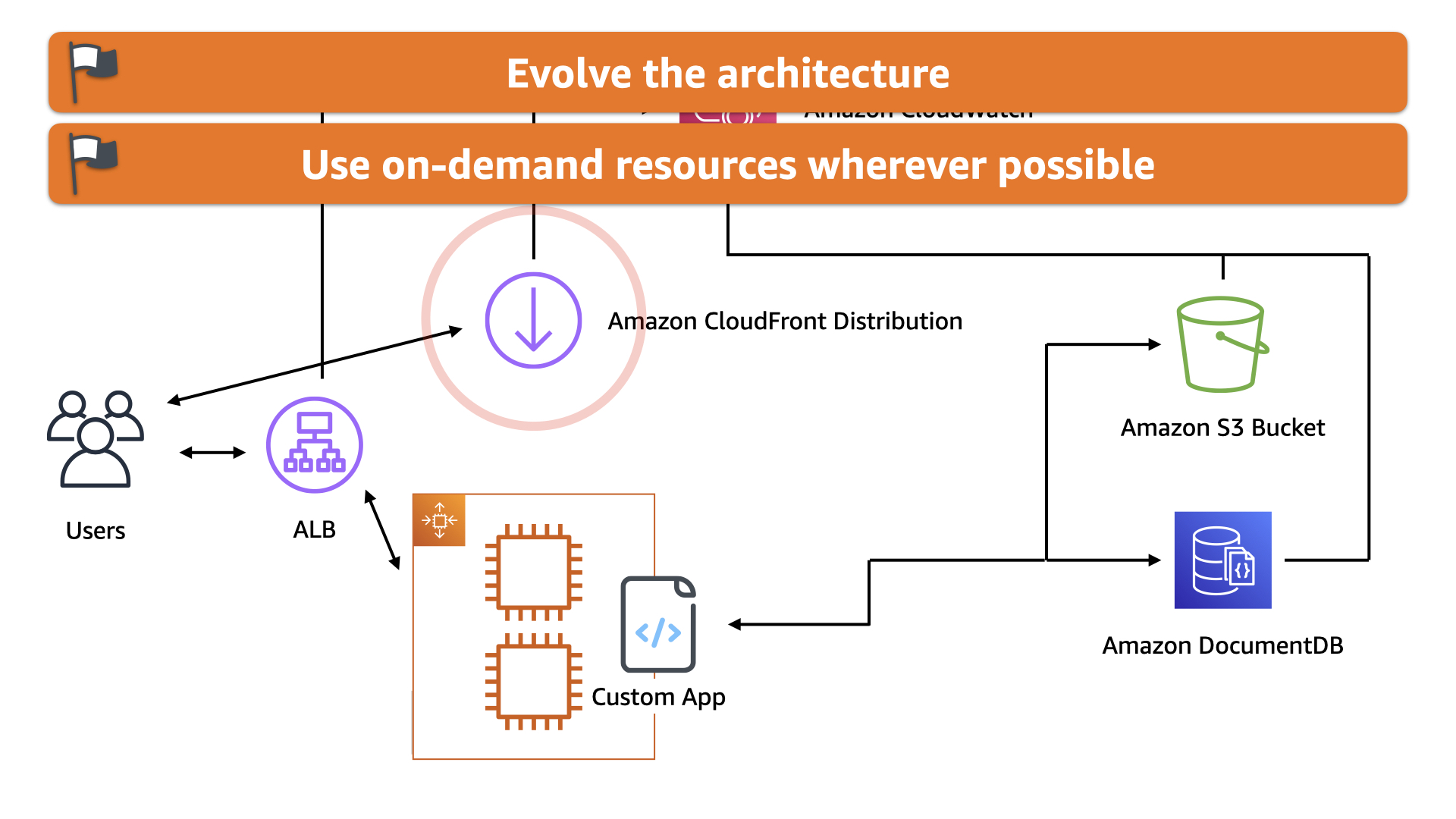
This also aligns with the principle of using on-demand resources wherever possible.
Yes, the EC2 instances were literally called "on-demand" but they still had idle capacity. CloudFront is a direct dollar to customer expenditure. It's a better cost optimization for the team in this case

Circling back to the framework view, the team has improved cost optimization, reliability, and performance without degrading operations or security
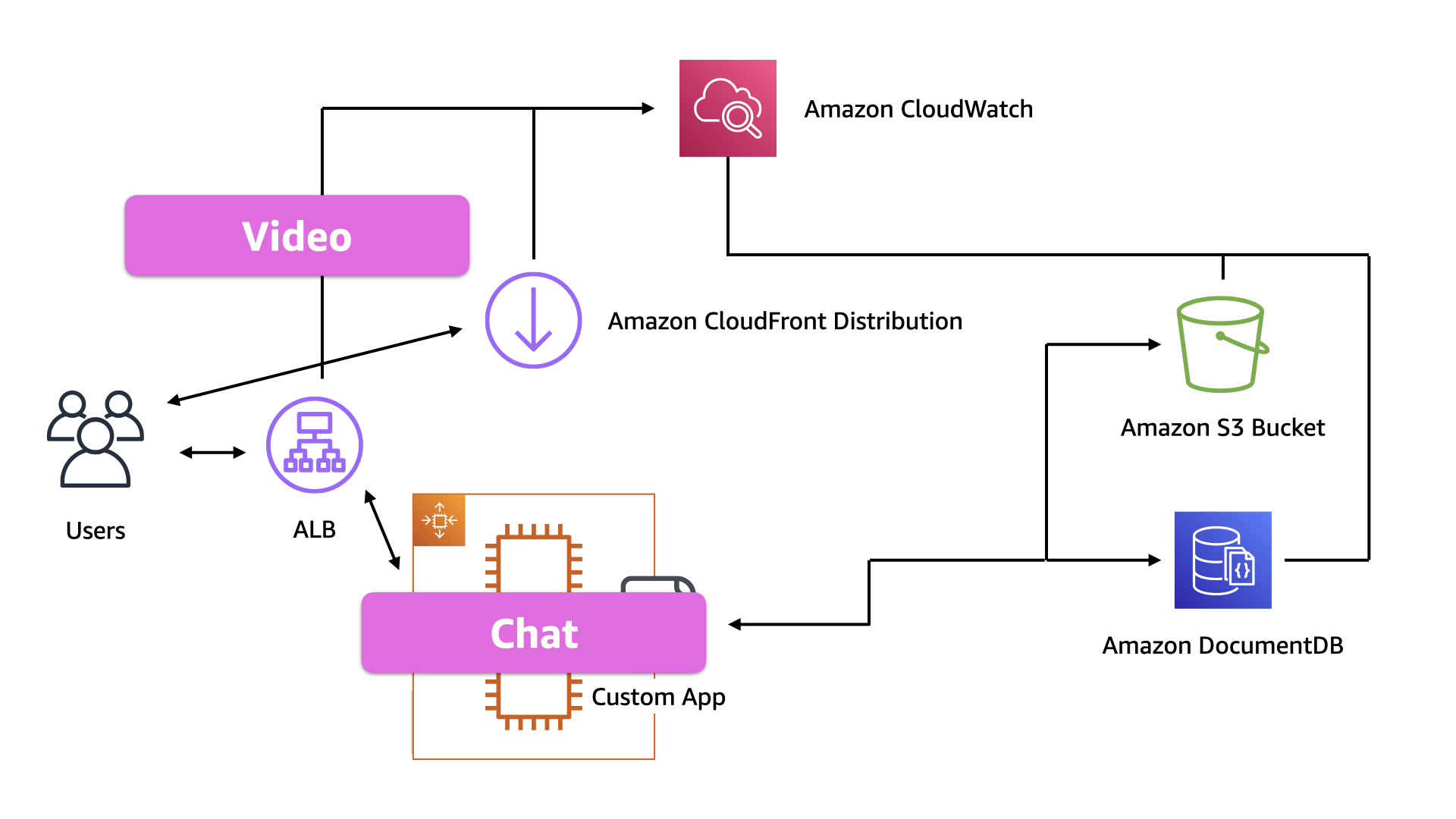
Looking at the current stage of the architecture, the team started to examine the chat portion of the solution. The EC2 instances were working but unnecessarily "heavy"
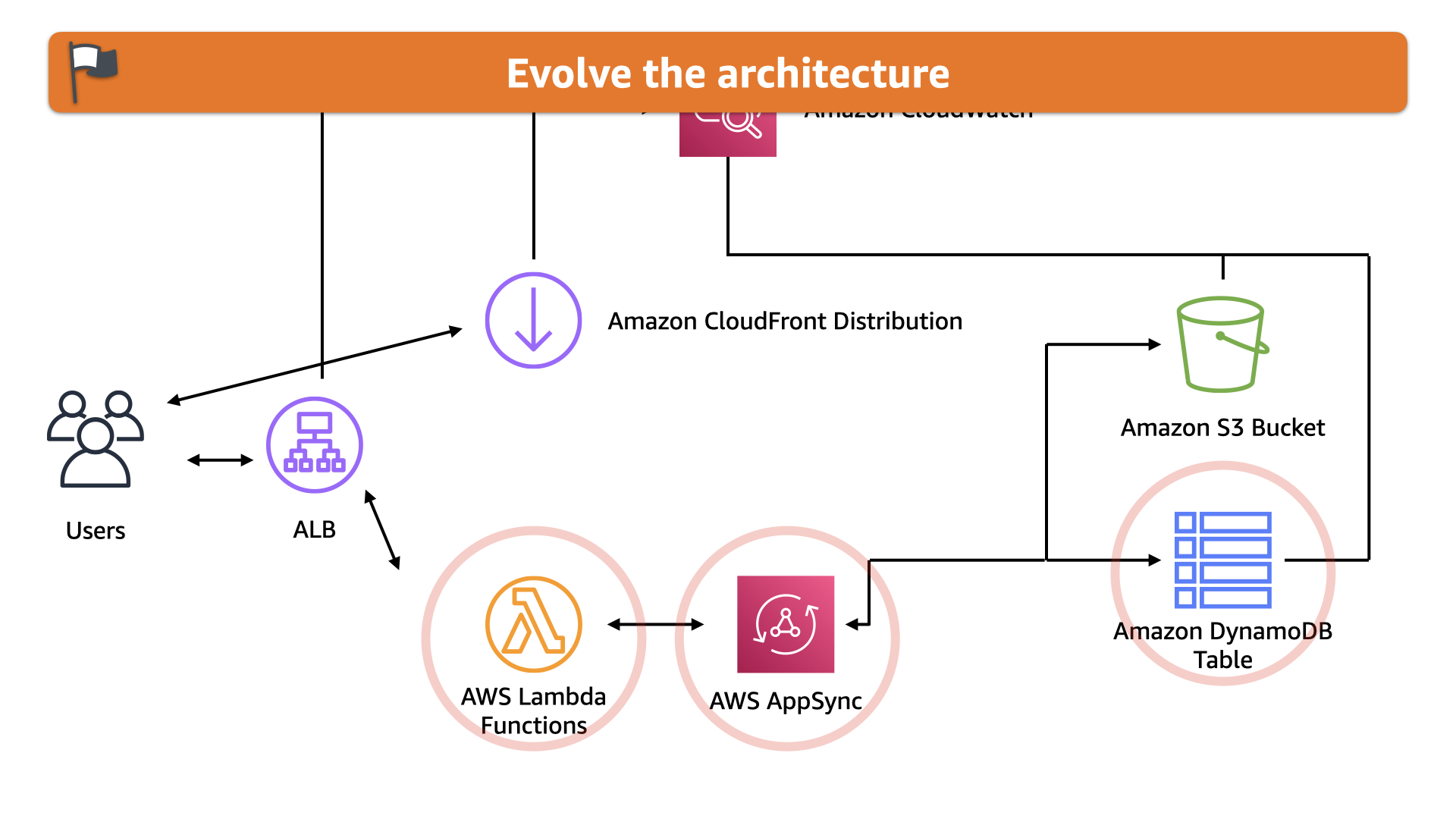
Thankfully, there's literally an AWS blog showing how to build a real-time serverless chat app. That was a good place to start
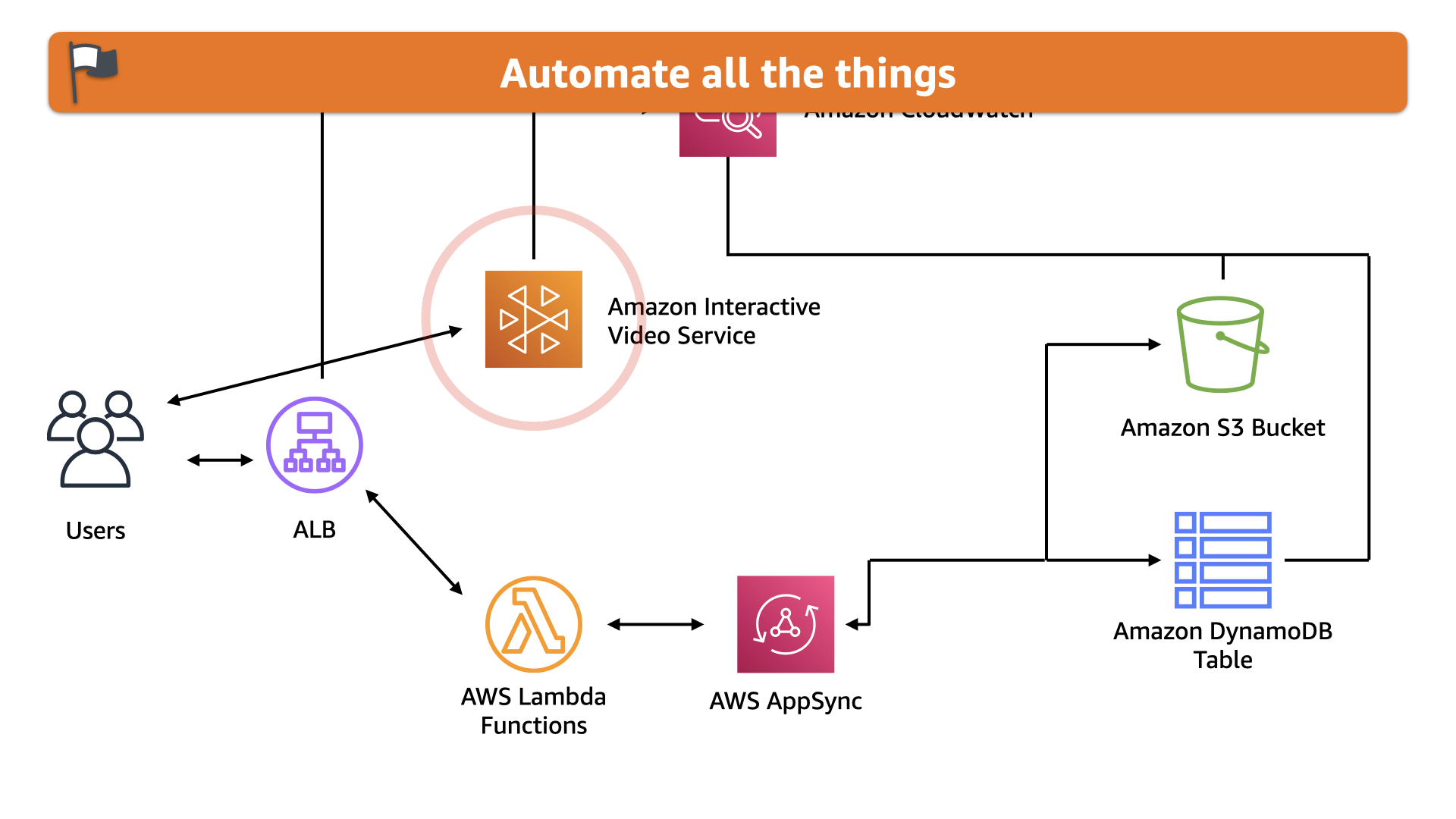
The last piece the team has started is shifting away from Amazon CloudFront to the new Amazon Interactive Video Service.
While it might seem needless, this provides some useful automation for the team. This lowers the operational burden and lets them focus on other areas...like feature delivery and reliability

Looking back at the team's progress, we see by applying the principles of the AWS Well-Architected Framework, they've made improvements in all areas...and more importantly delivered a much better customer experience!

The next story centers around a legacy system data storage challenge
In this case, a team had a large scale IoT solution that had been running for a while on-premises. Yes, on-premises.
This solution in the scientific space was bringing in a lot of revenue and was rock solid.
The premise is simple. Data is sent in real-time from devices around the world for centralized collections and analysis. The risk tolerance for downtime is low and customers are willing to pay for a high level of service
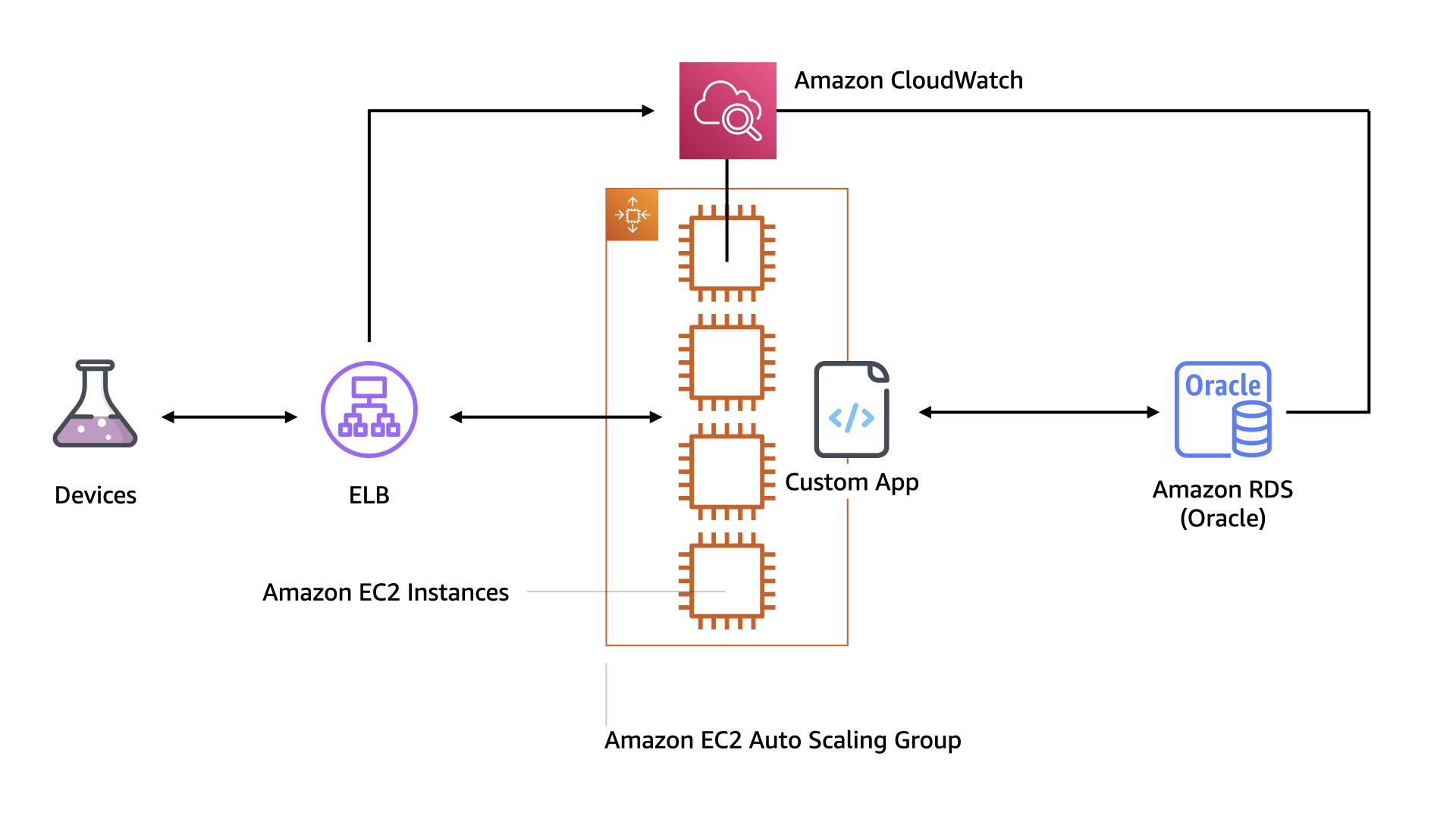
The team is moving to the AWS Cloud to as they look to evolve their architecture to meet changing customer needs and higher volumes of data.
Their first architecture in the AWS Cloud is a straight forward "forklift"
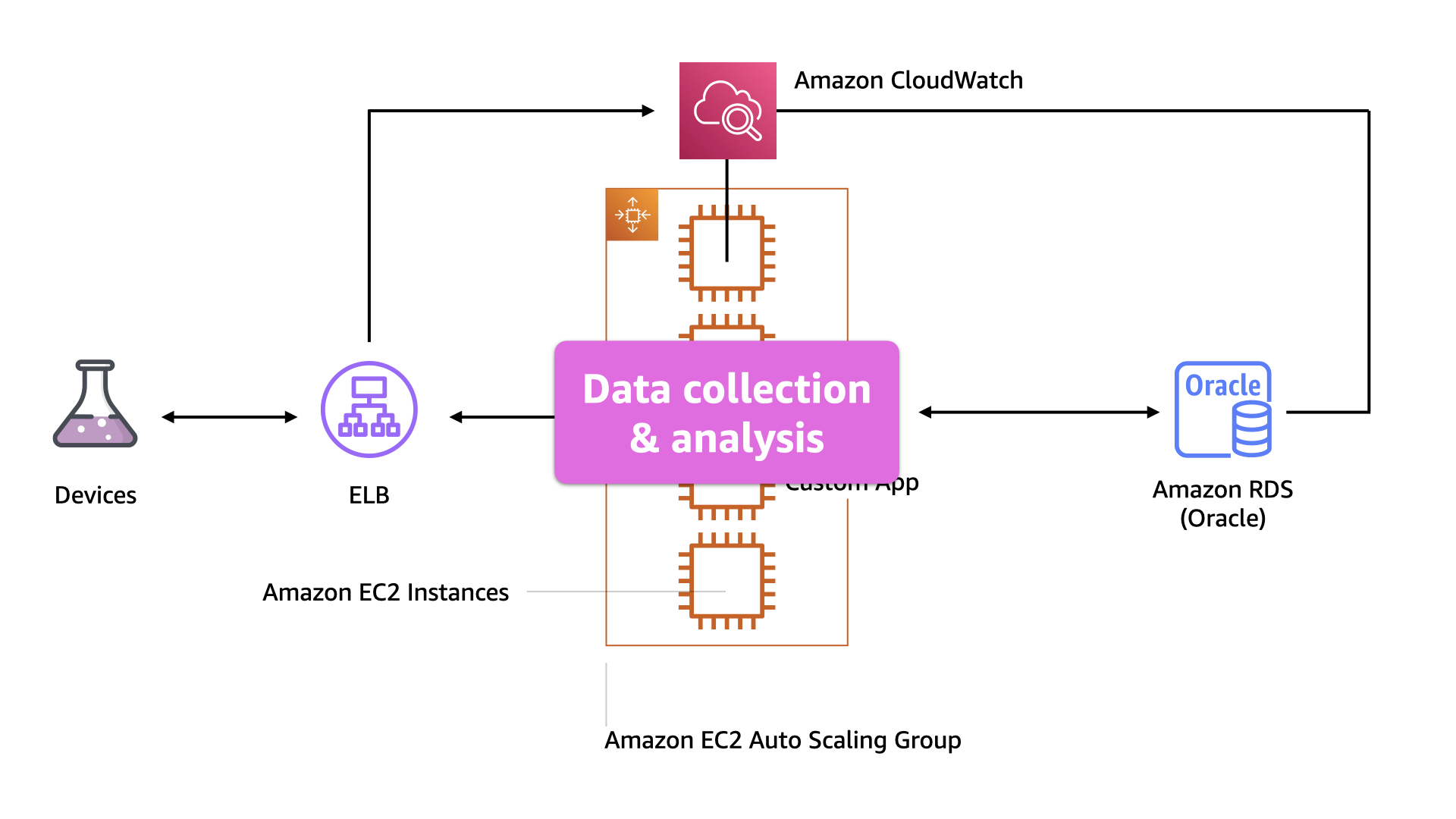
Again, the a weak point because of it's blast radius is that all of the data collection and analysis is done on a single auto-scaling pool of EC2 instances.
But that's not where this story is going to focus
Because the team has a lot of experience is keeping those instances up and running and that code is solid, they notice a growing challenge with the database.
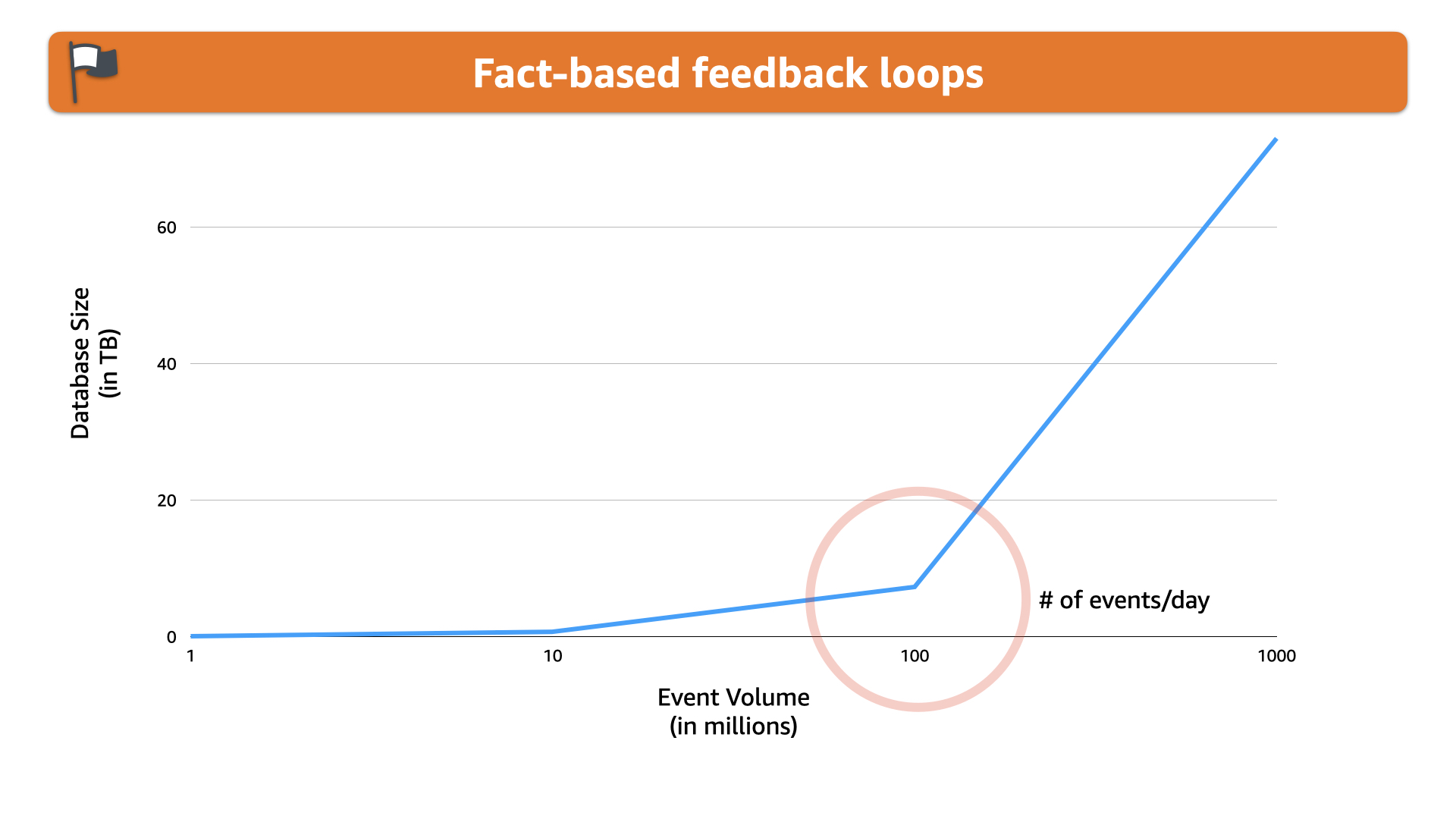
Currently, they have grown to ingest over 100 million events per day. That's about eight terabytes

The challenge is that using an RDS instance maxed out on storage size, they fill that storage space every eight days.
The cost is management but adding ~$15,000 USD every eight days to the bill is something that definitely stood out

Looking at this forklifted solution across the Well-Architected Framework, we see a reasonable set of results. Reliability is high (the thing their customers care about the most). The other areas could use some improvements though
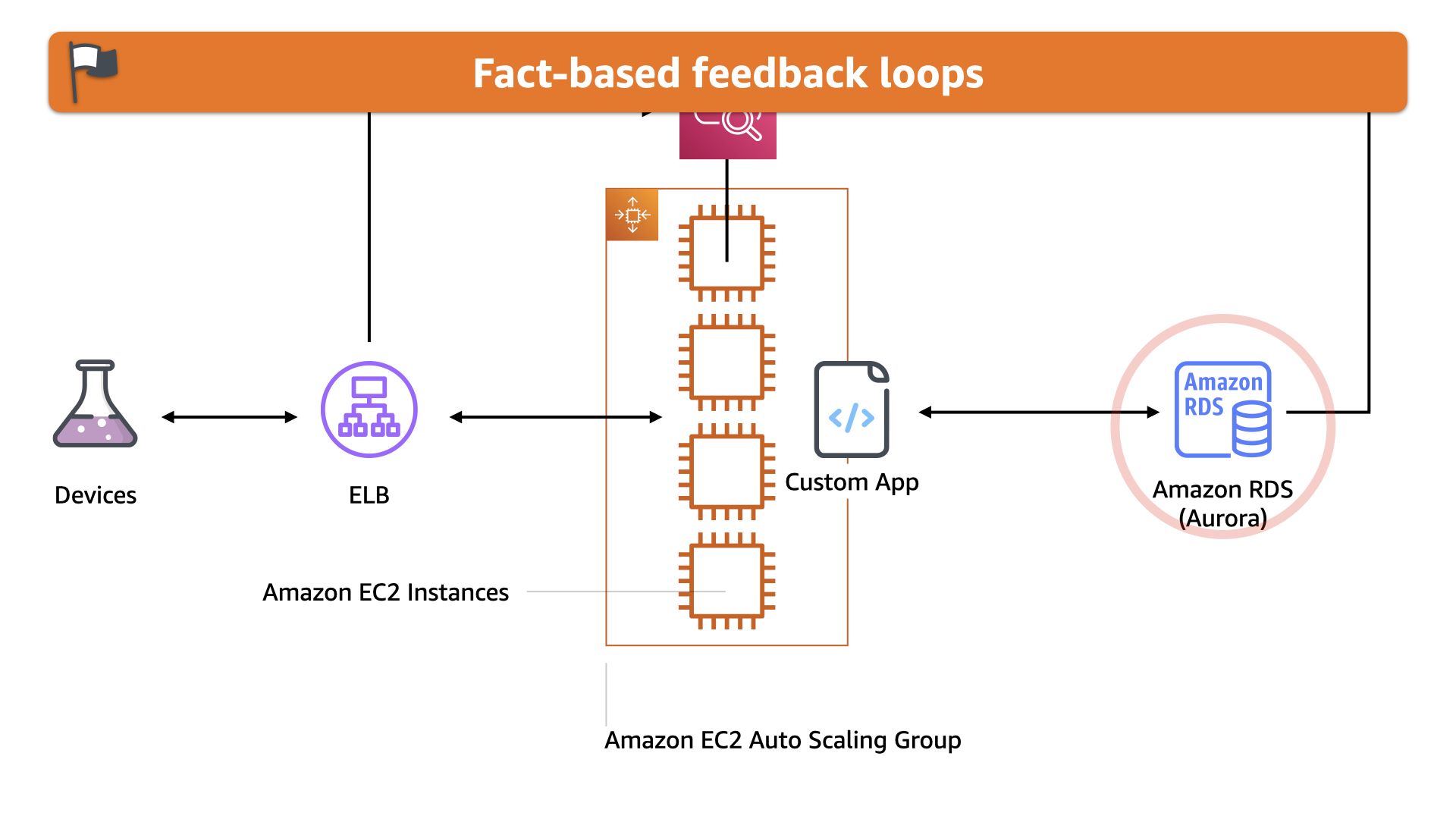
Using a fact-based feedback loop, the team knows the volume of data they are capturing and storing in Oracle just isn't tenable long term. They also know there are a host of better options available in the AWS Cloud

Changing out that Oracle RDS instances for an Amazon Aurora one is the easiest and lowest risk for this solution. It didn't take a lot of work to change the code to interact with Aurora and this change was completed in one sprint

The results were significant. An immediate savings of 49%. That's over $20,000 USD/month on usage charges, not to mention the significantly lower reservation costs!

If we re-evaluate the solution again the Well-Architected Framework, to no one's surprise cost optimization has increase significantly with this one move
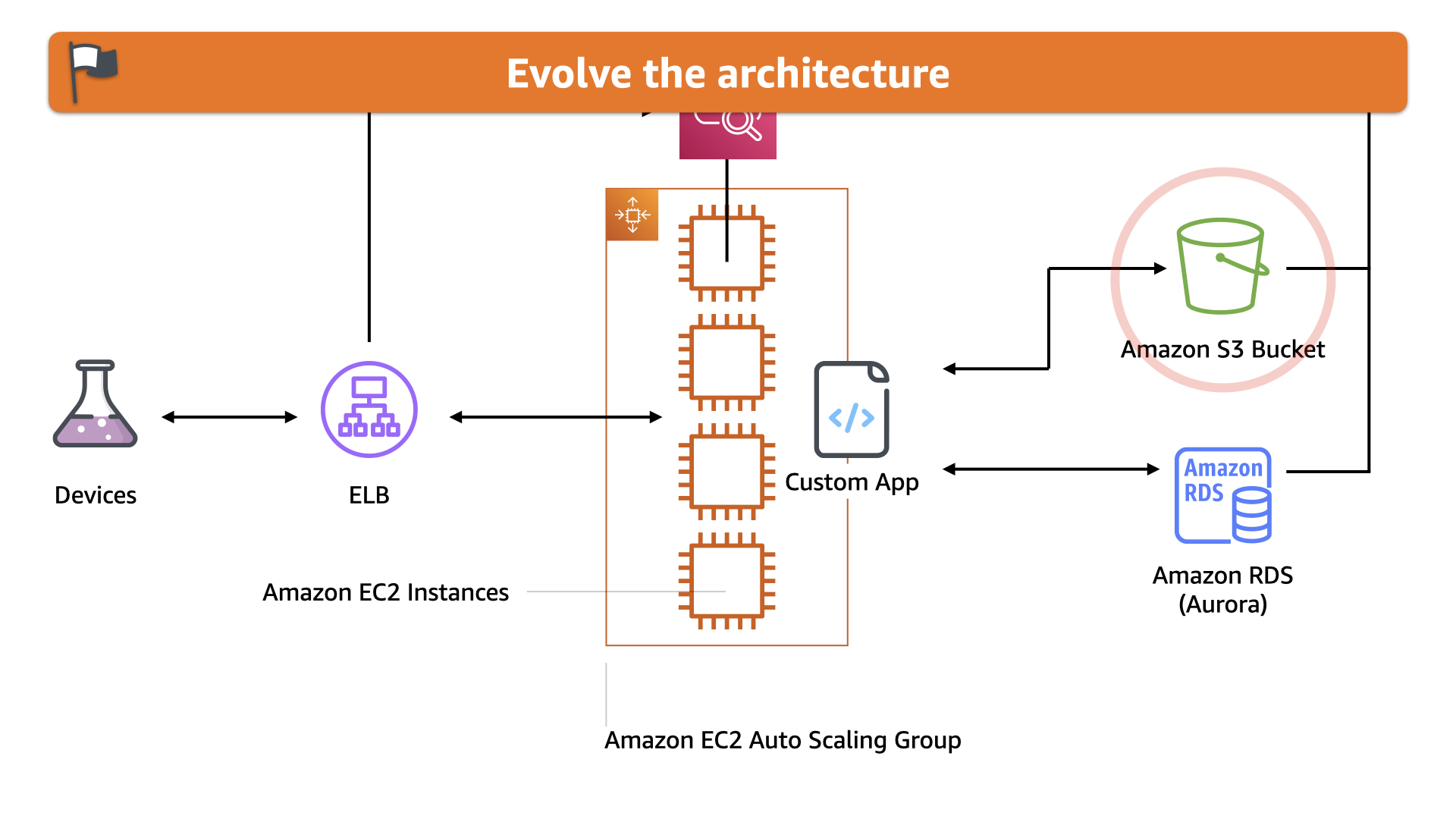
The next evolution the team undertook was removing older data from the Aurora database and storing it in Amazon S3. Older data has a very different use case in this solution and the high cost of storing it in a RDBMS just doesn't make sense anymore.
On-premises, the database was essentially a sunk cost. As long as there was enough storage on the storage area network, the solution was fine. In the cloud, this was inefficient
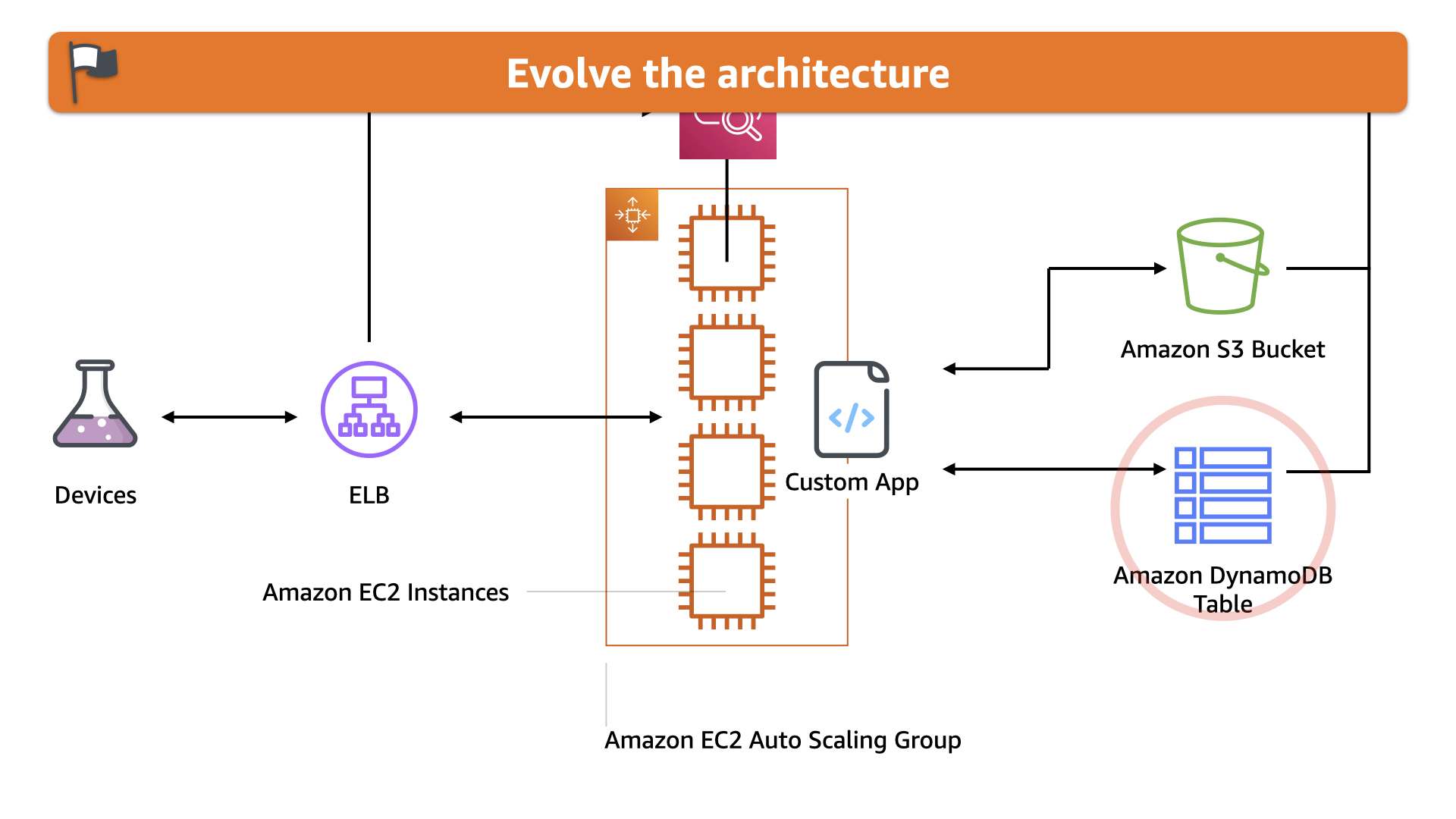
With older data moved to S3, the team realized they could streamline the real-time data using Amazon DynamoDB. This was actually less expensive, simpler, and provided a lot more headroom for scaling
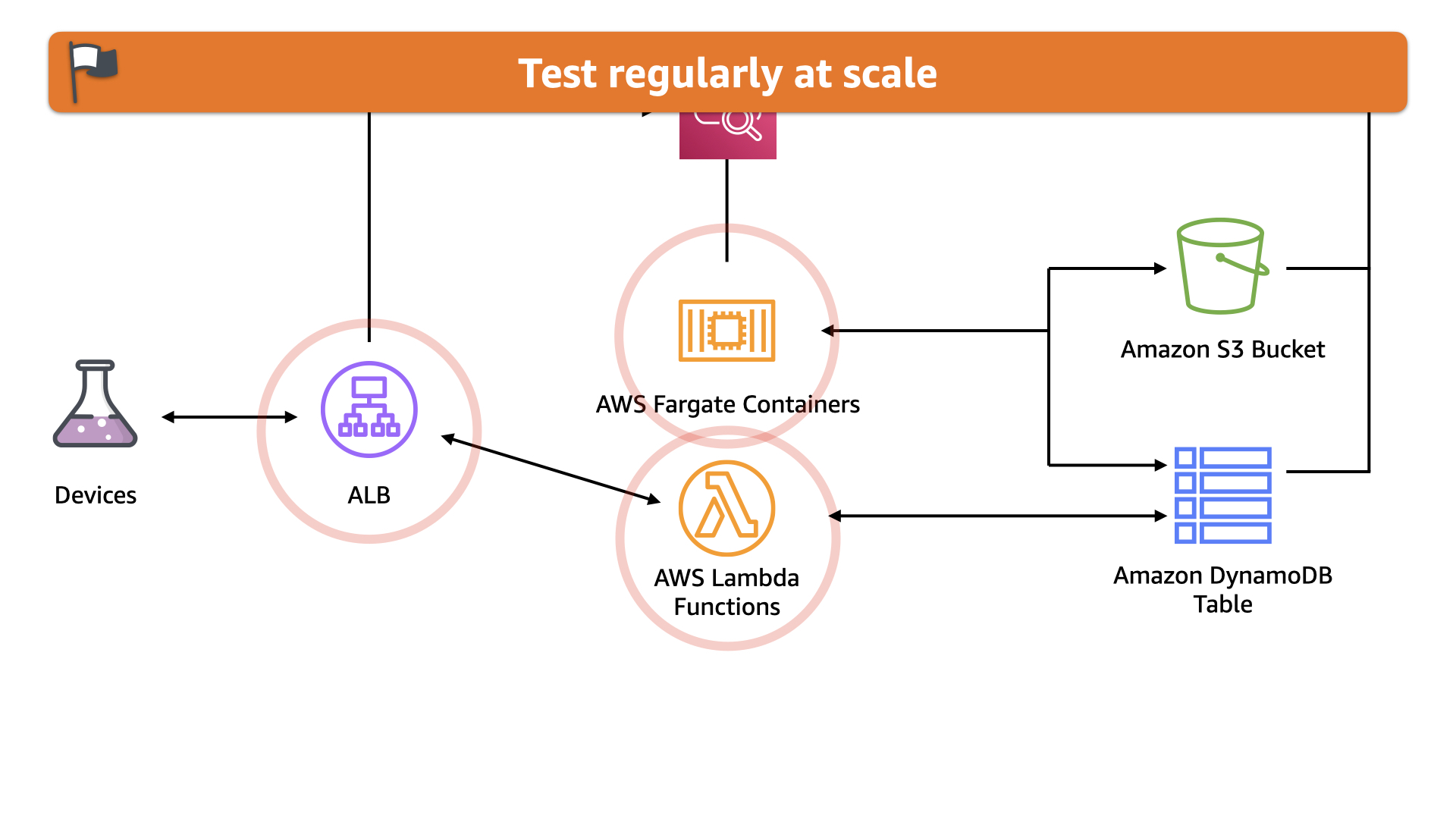
On a roll, the team migrated away from EC2 instances for compute. Analysis and batch processing is now done using AWS Fargate with only minor modifications to the codebase.
The real-time data is now process using AWS Lambda which is better aligned to the event style of the incoming data.
The team's tests reveal that this scales much better in response to customer demand because the batch analysis jobs no longer impact the real-time data processing and vice-versa
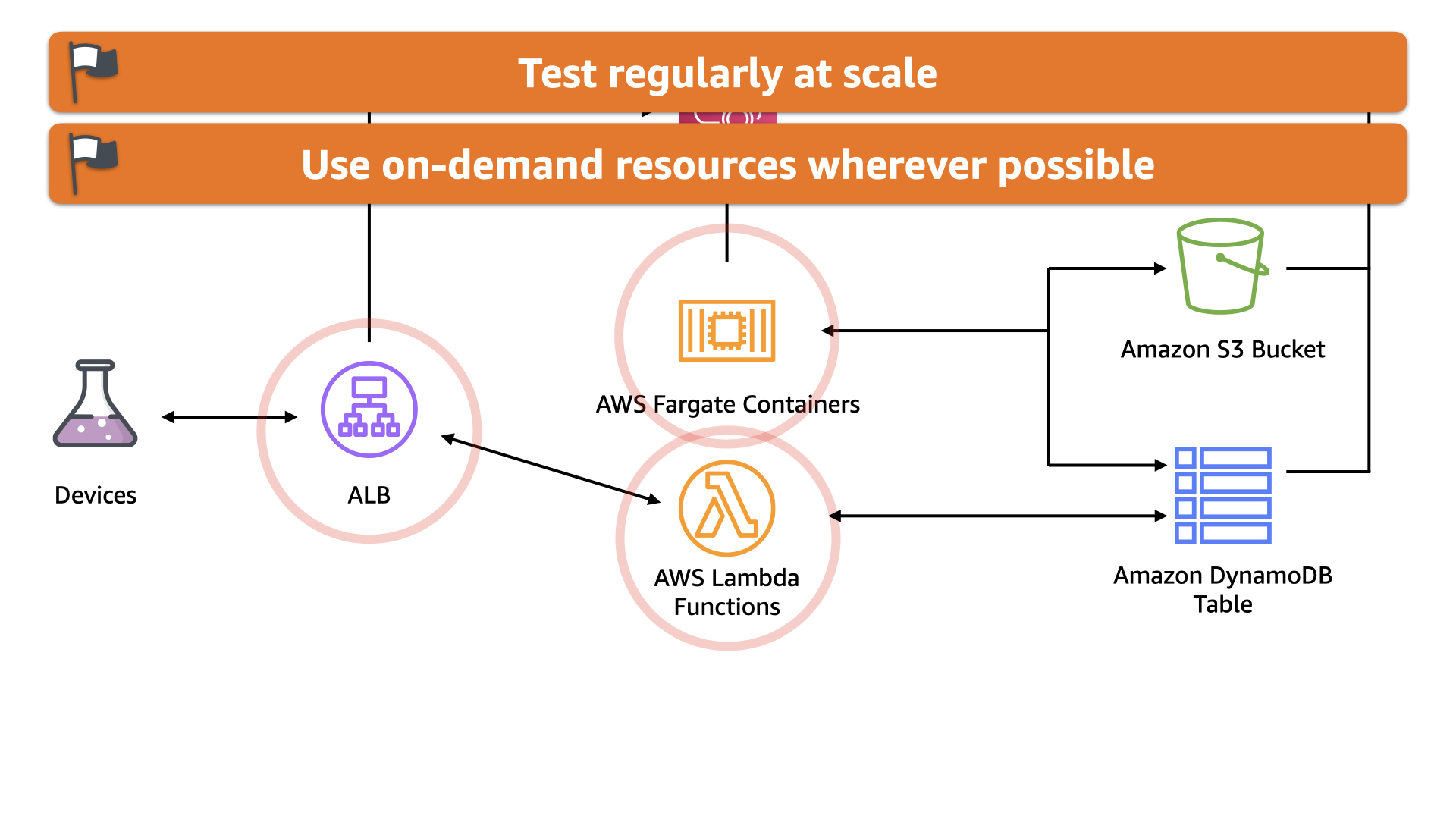
This also shifts the solution to align with the "Use on-demand resources wherever possible" principles. The AWS Fargate containers only run when there is an analysis job to complete. And the AWS Lambda functions are mapped 1:1 to incoming data
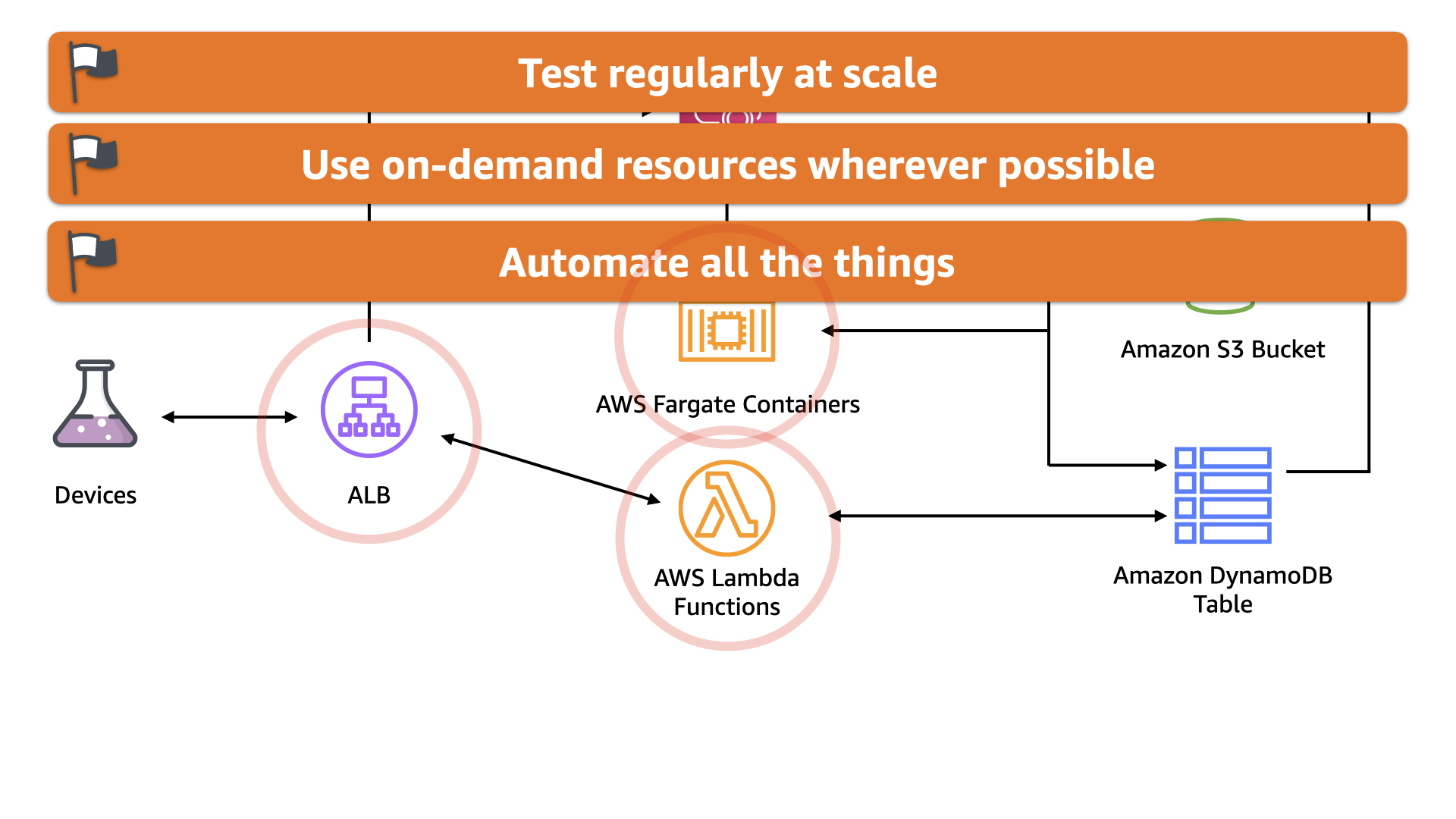
Finally, it also aligns with "Automate all the things" principle. The solution is now centered around various events and actions are fully automatic based on specific business criteria
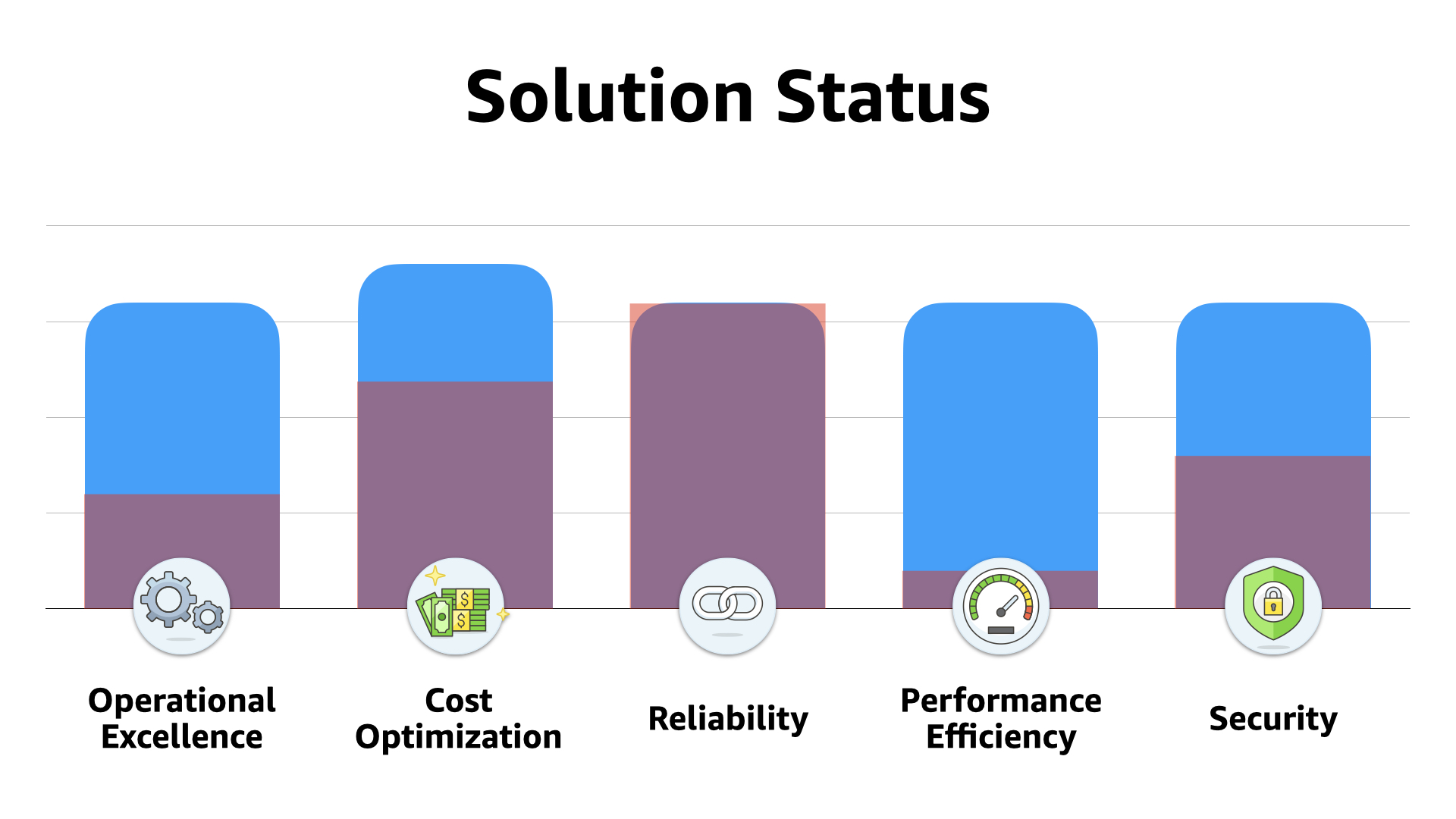
Looking at the overall position of the solution, we've seen improvements in every area except reliability. It was already sky high when the team started.
The important takeaway here is that they were able to re-architect the solution to be cloud native without sacrificing any of that reliability

Takeaways

The AWS Well-Architected Framework isn't a collection of best practices. It's a series of principles that will help you build better.
It's about finding the best solution for your challenge at the time

You can practice the framework by regularly and consistently applying it's principles

Those principles are;
- Use on-demand resources whenever possible
- Automate all the things
- Test regularly and at scale
- Fact-based feedback loops
- Evolve architectures
- Practice, practice, practice
The framework makes it easier to dive deeper by breaking up the content across five pillars;

Just remember, take your ideas, try them, learn from them, and repeat.
That's how you can build better in the AWS Cloud.

Thank you for reading/watching this session. And thank you to Trend Micro for sponsoring this session and providing me the space to teach the framework to even more builders